Zwei Doofe ein Gedanke.. @Dr.Big  Danke für die Erstellung des Themas.
Danke für die Erstellung des Themas.
Dann fange ich mal an zu berichten. Aktuell nutze ich ein MacStudio mit 36GB RAM. Das läuft wesentlich besser wie der mac mini (5x höherer Speicherdurchsatz). Wichtig ist mir dabei auch der Aspekt des Stromverbrauches. Wenn die KI dann wirklich mal längere Zeit läuft, soll sich der Verbrauch in Grenzen halten. Daher bin ich jetzt auch beim Mac gelandet. Mein normaler PC mit RTX4070 mit 12GB DDR6 und I9 9900K ist ebenfalls schon ziemlich flott, aber auch beschränkt wegen dem kleinen VRAM Speicher. Auf jeden Fall zieht der Rechner dann ordentlich Leistung im Vergleich zum Mac und ist nicht für 24/7 ausgelegt. Soviel zur Technik.
online
Ich verwende diverse KI-Modelle und kommt auch immer wieder auf den Einsatzzweck an.
Diese nutzte ich online im Browser oder als Tool auf dem PC/Mac. Alle in der kostenlosen Variante.
Gemini
Daily driver, für Fragen oder kleinere Aufgaben (Bilderstellung, Texte, manchmal HA Zeug)
Ist halt auch auf dem Handy immer dabei, daher einfache Nutzung für solche Dinge.
chat-gpt
Für Umwandlung von Texten in Markdown (wobei das gemini jetzt auch endlich kann)
HA Automatisierung, die dann an meine Sensoren angepasst werden
kleine Codeaufgaben die nicht lang sind (Phyton, Websiteoptimierung oder -Seiten)
claude
schon wirklich bemerkenswert wenn es um Code Sachen geht, nutze aber nur die Browservariante, kein Cowork oder Claude Code. Dafür nutze ich VScode.
Bei github habe ich eine subscription für 10€ und wurde zum Glück nicht gekickt. Aktuell kann man dort keine Abos mehr abschließen. Darin ist dann gpt und sonnet enthalten mit Kontingent.
local
Unter Proxmox läuft eine VM mit dem hermes agent (ganz ähnlich openclaw). Hier nutze ich für daily Sachen die freien LLM von openrouter. Da gibt es immer wieder neue und sind auch wirklich ganz gute dabei. Vor kurzem war auch qwen3.6 eine zeitlang kostenlos nutzbar. Der Agent kann dann schon bessere Aufgaben übernehmen (nutze ich für Arbeit mehr wie privat). Aber der kann dann seine zugeteilten Aufgaben abarbeiten und macht seine Arbeit im Hintergrund. Läuft über telegram und kann daher auch von überall gesteuert werden. Alles was dann komplizierter wird mache ich mit lokalen Modellen, die in LMStudio laufen. oMLX kannte ich noch nicht! Danke dafür, gleich mal installiert. Muss ich aber noch testen im Vergleich zum LMStudio. Trotzdem ist das mit dem Agent mehr Spielerei für mich.
Fürs Programmieren habe ich früher schon vscode genutzt, also ab 2016 oder so. Davor war Notepad++ mein geliebtes Tool und ist auch heute noch im Einsatz. Damit komme ich persönlich besser klar, wie mit dem Agenten, weil ich den code direkt sehe, eingreifen und mit der KI sozusagen zusammenarbeiten kann.
Die lokalen Modelle werden immer besser und bin gespannt wo da die Reise hingeht. Ich habe für mich immer einen kleinen Test, sobald ein neues Modell zum Einsatz kommt. Das lässt sich dann gut vergleichen und man hat direkt eine Vorstellung wie schlau die KI ist. Kommt natürlich auch wieder auf dein Einsatz an, aber bei mir ist das zum großen Teil Code. Kann das Modell die Aufgabe nicht erfüllen, fliegt es auch schon wieder runter. 
Prompt:
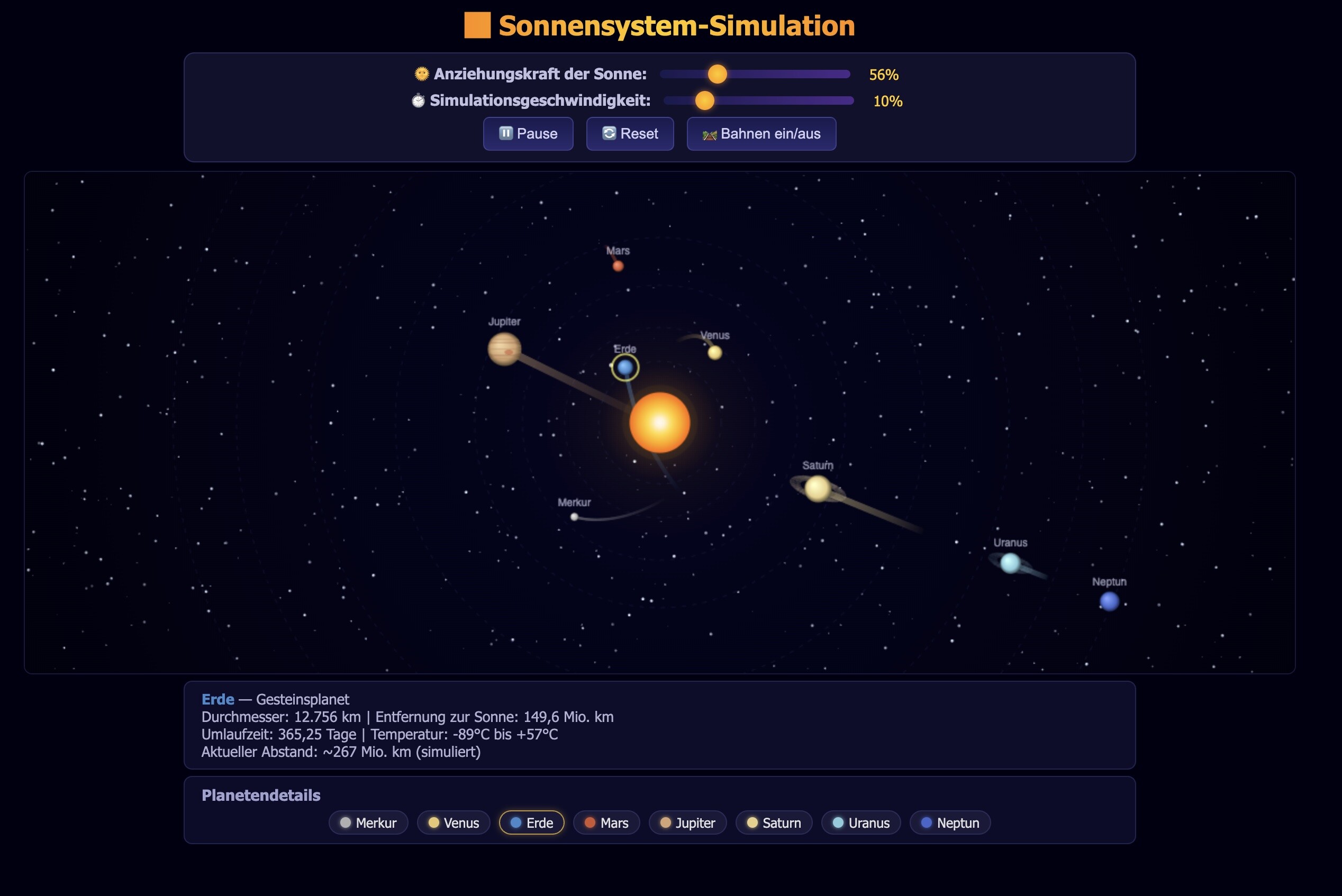
Erstelle bitte im Ordner mit Namen XXX eine standalone HTML Page die mir das Sonnensystem mit seinen Planeten zeigt. Die Seite soll aus drei Dateien index.html, css und javascript bestehen. Es soll einen Slider geben, so dass man die Anziehungskraft der Sonne einstellen kann.
Mehr wird nicht mitgeteilt und dann lasse ich mich überraschen, alles nach dem ersten Versuch.
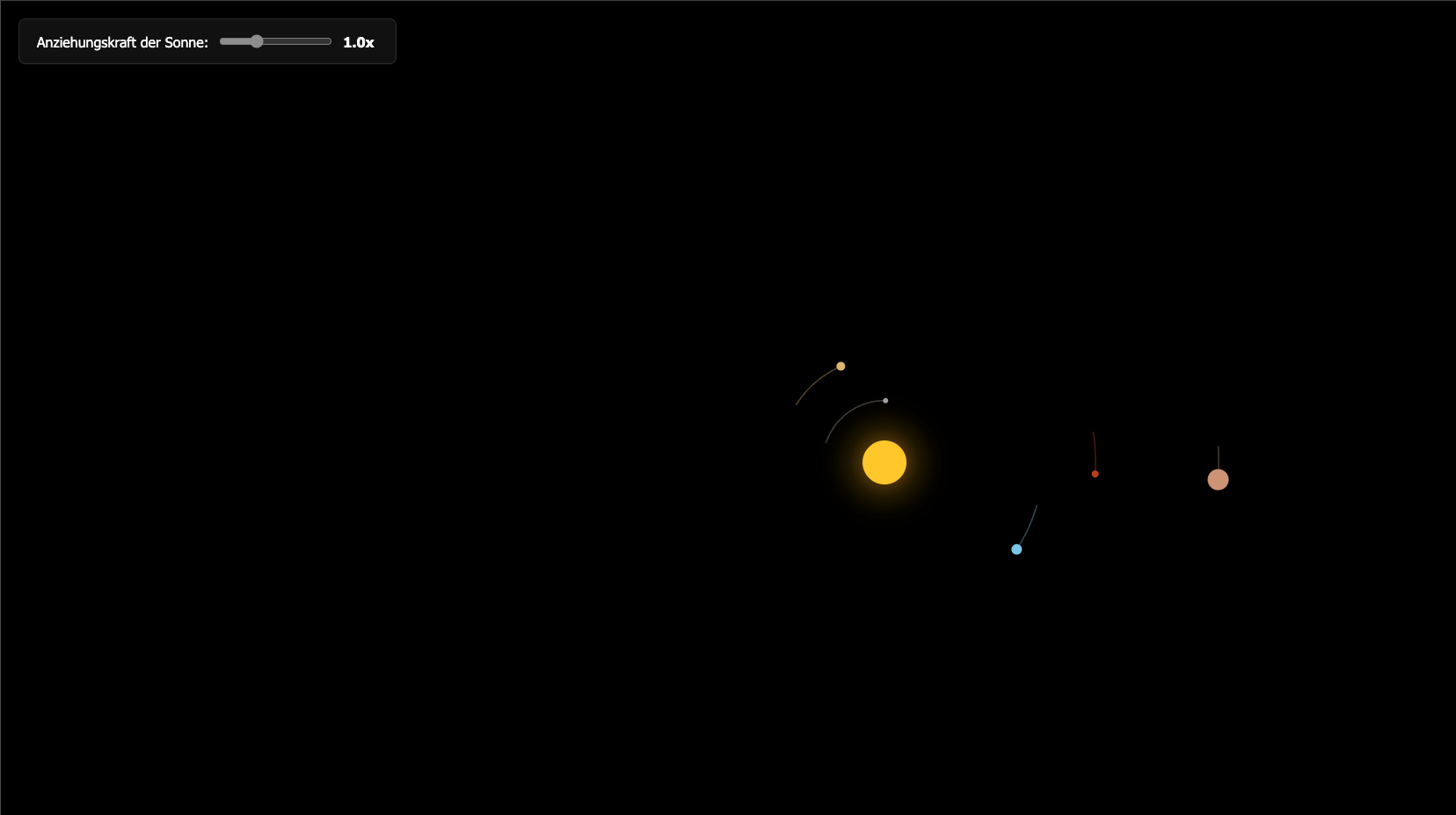
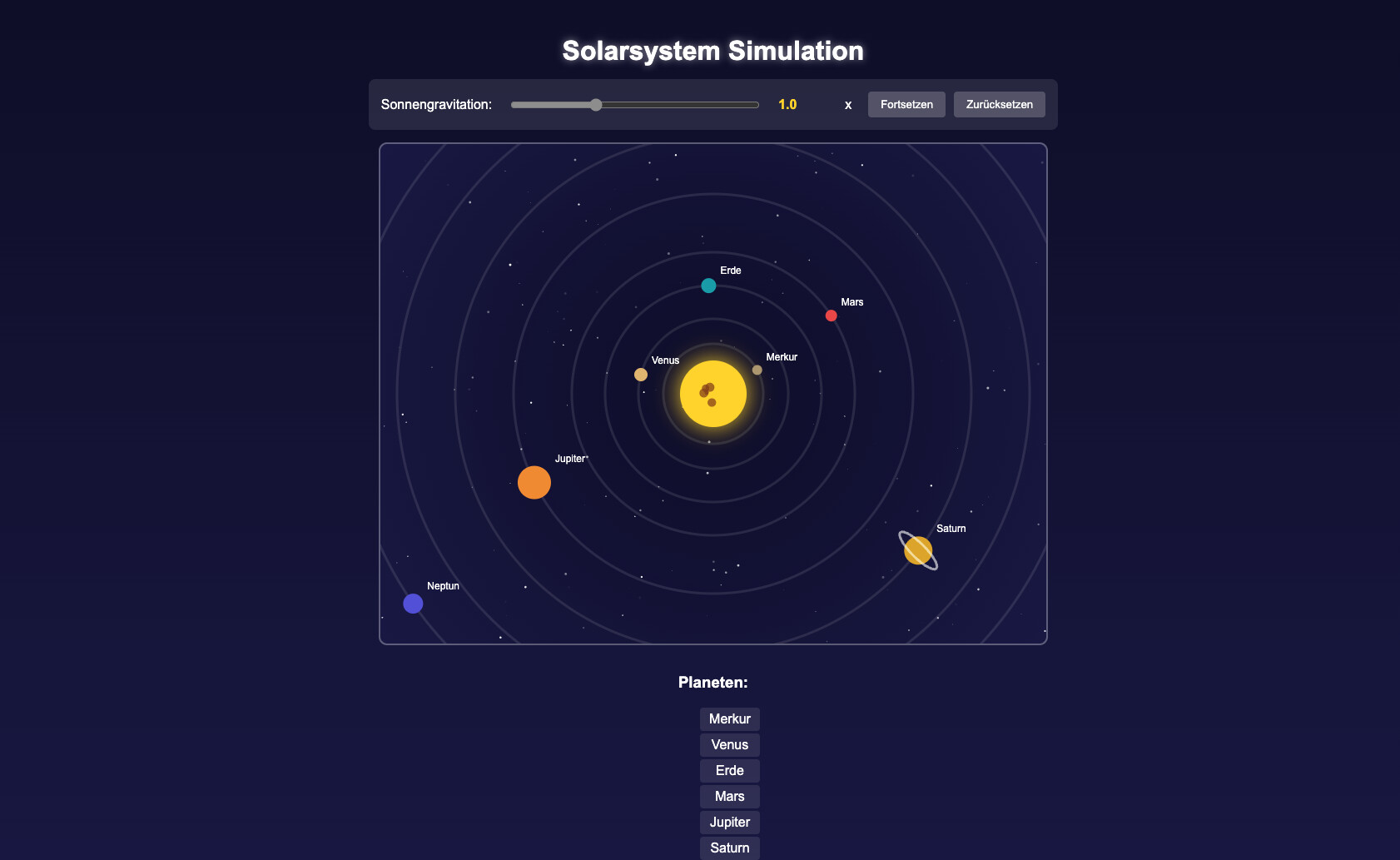
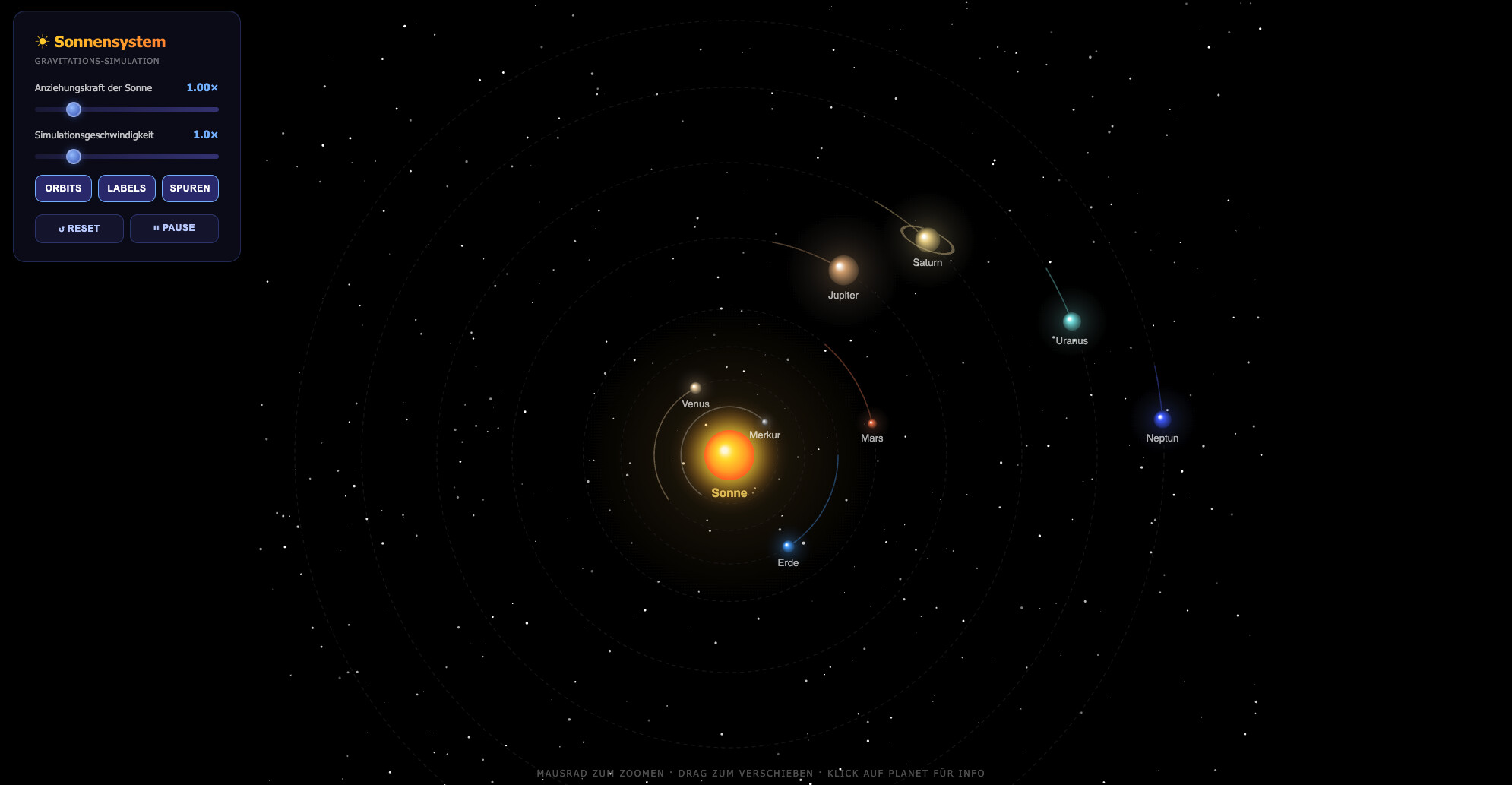
Hier mal die Ausgabe von meinen zu letzt getesteten Modellen, alle in Q4:
gpt-oss-20b
gemma4 26B-A4B
gemini (weil die KI jetzt auch Dateien direkt erstellen kann) (nicht lokal)
qwen3.5-9B
qwen3.6-27B
Testsieger ist eindeutig qwen3.6, schon allein die detaillierte Planetendarstellung schaut richtig gut aus. Qwen3.5 ist dicht auf, aber die Animation war falsch berechnet und daher haben sich die Planeten extrem schnell gedreht. Im Code waren das nachher drei oder vier Zeilen ändern, aber wenn ich ihm das gesagt habe, hat er es trotzdem nicht hinbekommen. Gemini und Gemma haben die Seiten soweit auch korrekt erstellt und die Animationen funktionieren, also besser wie qwen3.5.
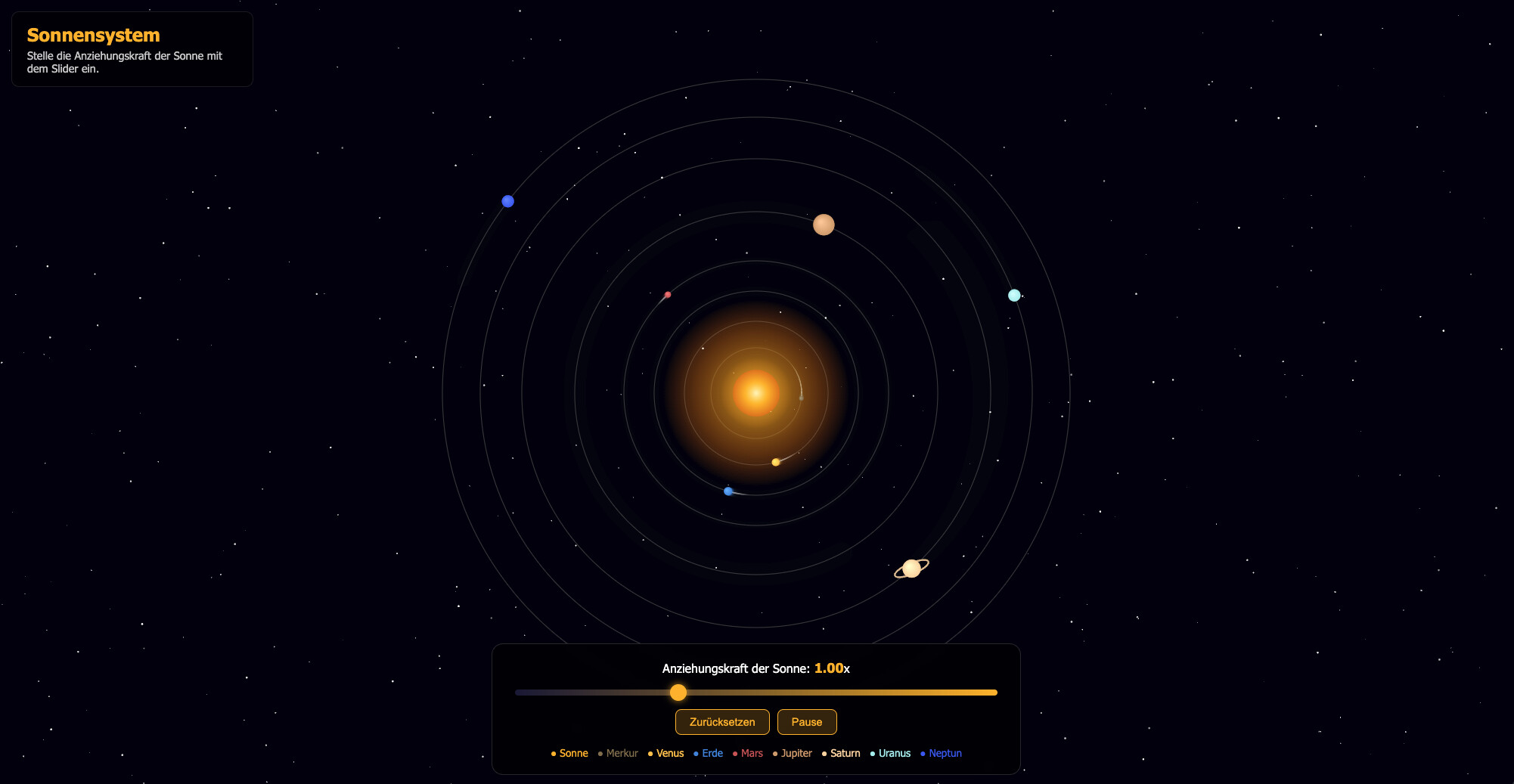
Zum Vergleich claude opus4.7 (online)
Aber hier wurde die Anziehungskraft falsch erstellt. Die Sonne wurde größer, aber die Umlaufbahnen haben sich nicht geändert. Erst nach Nachfrage wurde es korrigiert.
Noch ein Abschluss, wer eine offene Cowork Plattform sucht, kann sich mal AionUi anschauen. Damit kann man wiederkehrende Aufgaben einrichten, kann einen Webserver starten, so dass auch Messanger (Telegramm und Co) mit der Aion genutzt werden können. Es können sowohl lokale wie cloud Modelle verwendet werden und es ist ein nahtloser Übergang zwischen cloud und local session möglich. Habe ich auch gerade mal ein paar Tage installiert, aber gefällt mir bisher wirklich gut!
 Mac Mini / MacBook mit Apple Silicon?
Mac Mini / MacBook mit Apple Silicon? PC mit Nvidia GPU?
PC mit Nvidia GPU? NAS (Synology, TrueNAS)?
NAS (Synology, TrueNAS)? Mini-PC (N100, Beelink)?
Mini-PC (N100, Beelink)? Oder doch Cloud (ChatGPT, Claude)?
Oder doch Cloud (ChatGPT, Claude)?