5 Minuten nicht aufgepasst schon sind die “Invasoren” da! ![]()
LMM-Test.zip.pdf (12,8 KB) (.pdf entfernen)
5 Minuten nicht aufgepasst schon sind die “Invasoren” da! ![]()
LMM-Test.zip.pdf (12,8 KB) (.pdf entfernen)
Habe OpenWebUi als LXC laufen mit Ollama und OpenRouter Ai. das ganze ist zur Zeit auf einer Speichergröße von 50GB installiert, wollte jetzt in Ollama deepseek-v3 installieren, da habe ich gesehen das er über 400GB dafür herunterladen würde. Das wird bei 50GB Speichergröße schwer gehen. ![]() Wie groß sollte man für die Installation von Ollama mit OpenWebUI und OpenRouter Ai nehmen, reicht eine 2TB NVMe?
Wie groß sollte man für die Installation von Ollama mit OpenWebUI und OpenRouter Ai nehmen, reicht eine 2TB NVMe?
Was für eine Hardware hast du denn dass du solche Modelle ausführen kannst? Das Modell mit 400GB hat 761B Paramter. Ich glaube kaum, dass die Festplattengröße da der limitierende Faktor ist. Ich bezweifle, dass das auf durchschnittlicher Consumer-Hardware ansatzweise läuft
Ok dann muss mal schauen welcher Parameter dort steht! Dann sollte ich eher an solchen Modellen halten? llama3.2 Bin einfach bei dem ganzen noch am Anfang mit meinem Wissen!
Ja, genau! Die verlinkten Llama Modelle haben bspw nur 1B und 3B, das ist schon deutlich weniger ![]() Die Parameter geben einfach an, wie gut ein Modell trainiert wurde und daher auch wie ressourcenintensiv ist. Je nach Hardware sollte man dann mal schauen. Auf mittlerer Hardware sind 1-10B Modelle ganz gut (so wie Llama 3.2) und bei besserer Hardware kann man auch gut mit besseren Modellen (70B+) testen
Die Parameter geben einfach an, wie gut ein Modell trainiert wurde und daher auch wie ressourcenintensiv ist. Je nach Hardware sollte man dann mal schauen. Auf mittlerer Hardware sind 1-10B Modelle ganz gut (so wie Llama 3.2) und bei besserer Hardware kann man auch gut mit besseren Modellen (70B+) testen
Ja, lieber langsam ran tasten!
Fang mit einem “kleinen” Modell an und dann bekommst du auch ein Gefühl dafür! ![]()
Eine Nummer größer ist immer nur einen Download weit entfernt. Und lass dir dein Modell ruhig von der “Online-Ki” erklären und auch was da für Anforderungen “Hardware” etc. bestehen.
Habe mir jetzt mal ein paar Erdklärvideos dazu angesehen und mal das ganze zu verstehen zu können. Jetzt weiß ich schon mal was die Größe für Auswirkungen auf das können der Modelle hat! Habe jetzt mal qwen 2.5 und llama3.2 laufen mit denen werde ich jetzt mal arbeiten! Free Online Modelle gibt es ja auch noch genügend wenn die zweit nicht mehr reichen würden!
Habe jetzt mal zwei kleine installiert qwen 2.5 und llama3.2 mit denen werde ich mich befassen! Für größere reicht der Speicherplatz jetzt nicht mehr aus! Sollen nur mal die ersten Gehversuche werde, später kann ich immer noch das ganze neu machen mit mehr Speicherplatz! Kommt mir vor wie vor langer langer Zeit mit dem ersten Kontakt mit WinXP und wie lange das System läuft bis man es das erste mal selber neu Aufsetzen musste und keine Ahnung davon gehabt hat! ![]()
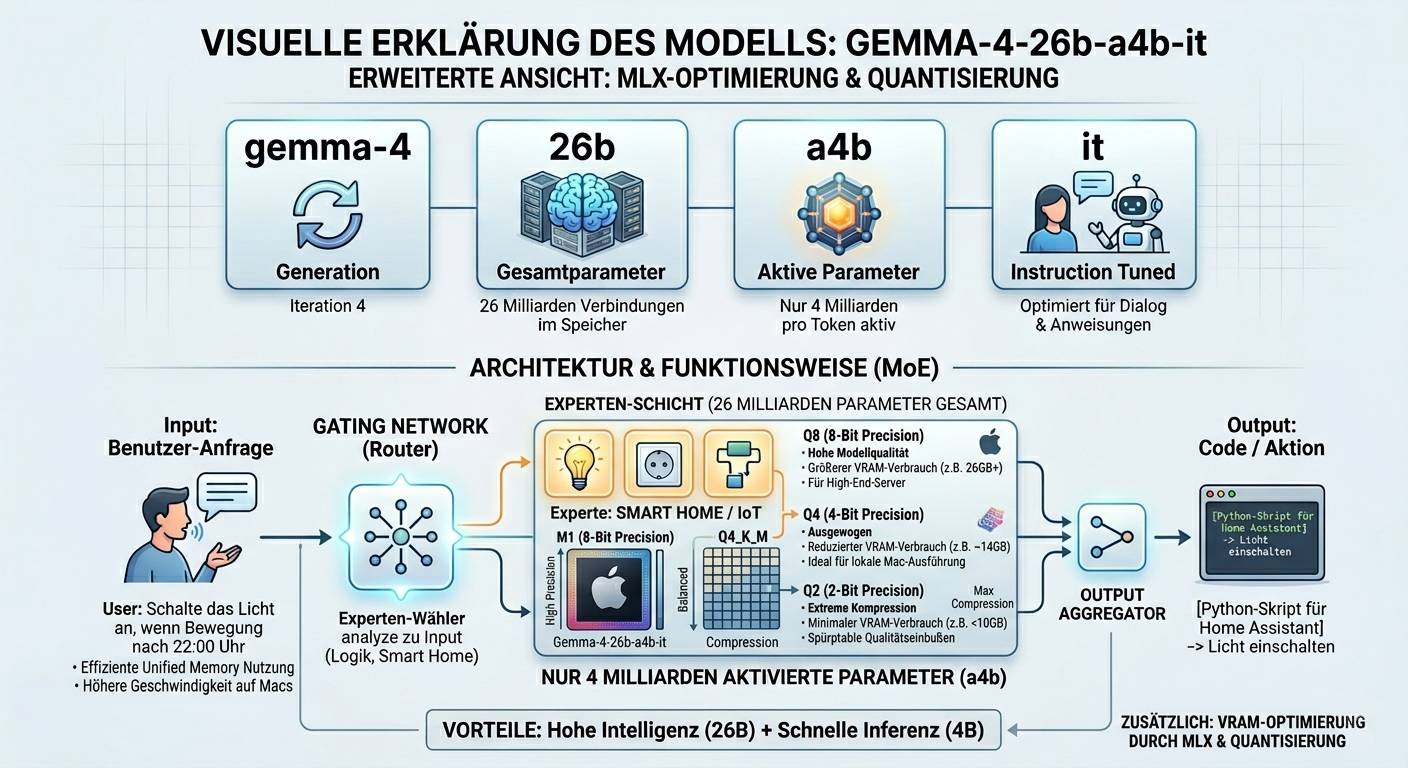
Hi, es werden sicherlich schon viele Wissen, wie man die Zahlen bei den LLMs zu intepretieren hat. Ich dachte aber auch so eine Erklärung hier im Thema kann nicht schaden, also habe ich mal eine Grafik erstellen lassen, die die Bezeichnungen im LLM Namen näher beschreibt. Es gibt doch einige Zahlen auf die man in Bezug auf seine Hardwareausstattung wirklich achten sollte.
Letztendlich sind höhere token/sec doch schöner. ![]()
Hinter der kryptischen Bezeichnung verbirgt sich eine klare Logik:
Da wir die Modelle lokal laufen lassen wollen (z.B. über Ollama, LM Studio, oMLX), müssen wir auch den Speicherverbrauch berücksichtigen. Die Quantisierung ist dabei quasi die Datenkompression des Modells. Höhere Zahlen sind hier immer besser. Das verhält sich ganz ähnlich zu Bildern in 4bit, 8bit oder 16bit.
| Level | Qualität | VRAM Bedarf | Empfehlung |
|---|---|---|---|
| Q8 (8-Bit) | Nahezu verlustfrei | Hoch (ca. 26GB+) | Für Server oder Workstations mit viel VRAM. |
| Q4 (4-Bit) | Ausgewogen | Moderat (ca. 14GB) | Sweet Spot für die meisten lokalen Setups. Kaum spürbarer Qualitätsverlust. |
| Q2 (2-Bit) | Spürbare Einbußen | Minimal (< 10GB) | Nur wenn der Speicher extrem knapp ist. |
Dann gibt noch MLX zu erwähnen, wobei das nur bei Apple zum Tragen kommt, soweit ich das verstanden habe. Wer also auf Apple Silicon (M1/M2/M3/M4) unterwegs ist, sollte unbedingt nach MLX-optimierten Versionen suchen. MLX ist ein Framework von Apple, das das Modell direkt auf die GPU-Architektur und den Unified Memory zuschneidet.
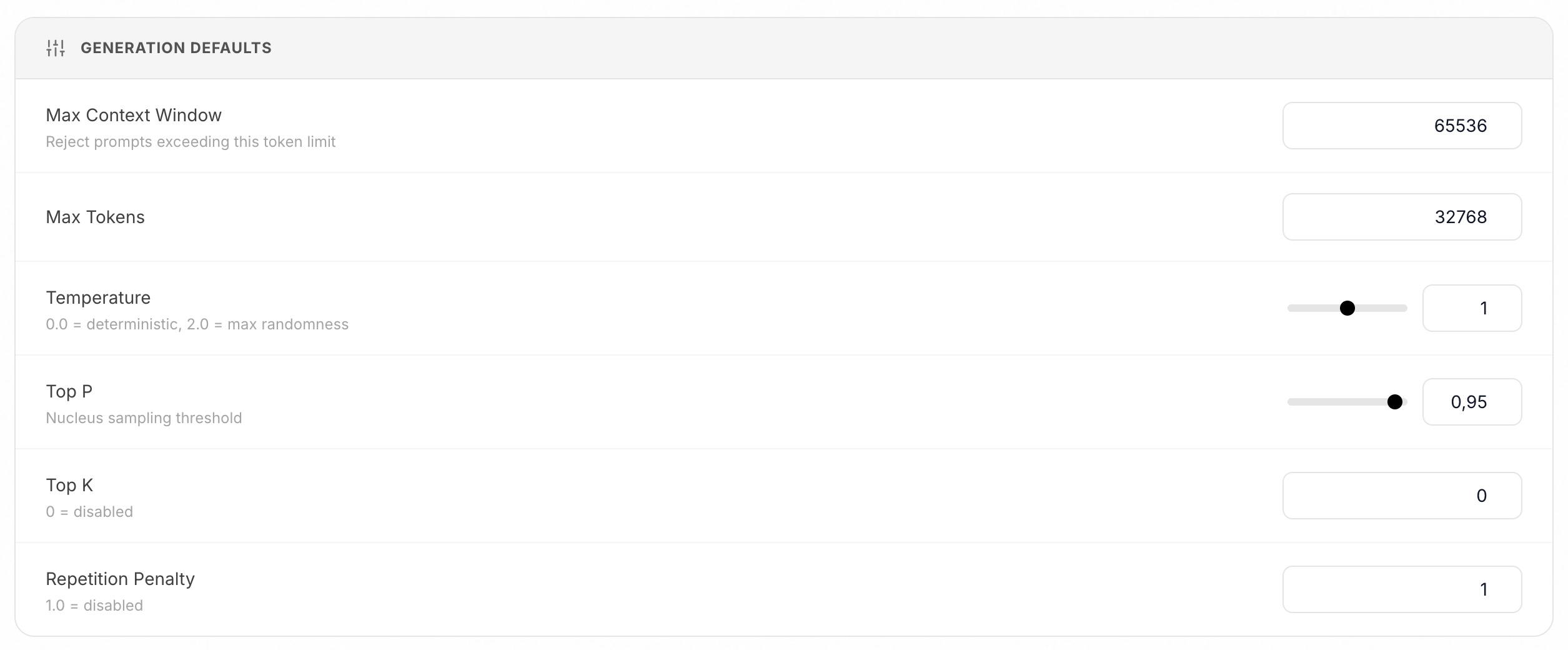
@Dr.Big oMlx scheint wirklich gut zu sein. Musste mich erstmal kurz reinfinden, wo man was einstellt und aktiviert. Aber dann läuft das wirklich schneller mit MLX. So läuft dann Qwen3.6-35B-A3B-UD-MLX-4bit auch bei mir. Habe dann etwas über 300Token/sec bei Generation und bei Output knapp 50 Token/sec. Damit kann man schon gut arbeiten. Wo stellst du die Contextlänge ein? Bei der Antwort bricht er auch gerne mal ab, weil die Max-Tokengrenze erreicht ist.
@mafe68 Wie schauen deine ersten Tests aus, bist du soweit zu frieden? Wieviel Token/sec bekommst du bei deinem Setup hin?
unter /Settings/GlobalSettings
und meistens deaktiviere ich im Modell selber “Enable Thinking” das bringt noch etwas mehr Geschwindigkeit! (Bei Bedarf kann man es ja wieder aktivieren!)
Enable Thinking habe ich immer an, dachte eigentlich das bewirkt auch etwas für einen besseren Output. Muss ich mal testen.
Ah, danke, habe ich gefunden. Aber das Max Context Window sollte möglichst groß sein, 65k sind da schon knapp. Habe auch gelesen, dass man die Temperature immer etwas herunter nimmt, so auf 0,6-0,8, dann fantasiert er nicht so sehr.
Da denkst du schon richtig! Aber probier mal was es in Sachen Geschwindigkeit bringt!
Für “harte Nüsse” dann halt wieder “zuschalten” ! ![]()
Qwen3-14B (habe ich bei mir aktuell als Default) und viele andere unterstützen bis zu 128K Kontext, du könntest also auch auf 131072 erhöhen wenn du sehr lange Gespräche mit viel Websuche führst
Habe ich auch schon probiert, gefühlt nicht viel Unterschied!
Ja Context ist immer wichtig, auch bei der Programmierung!
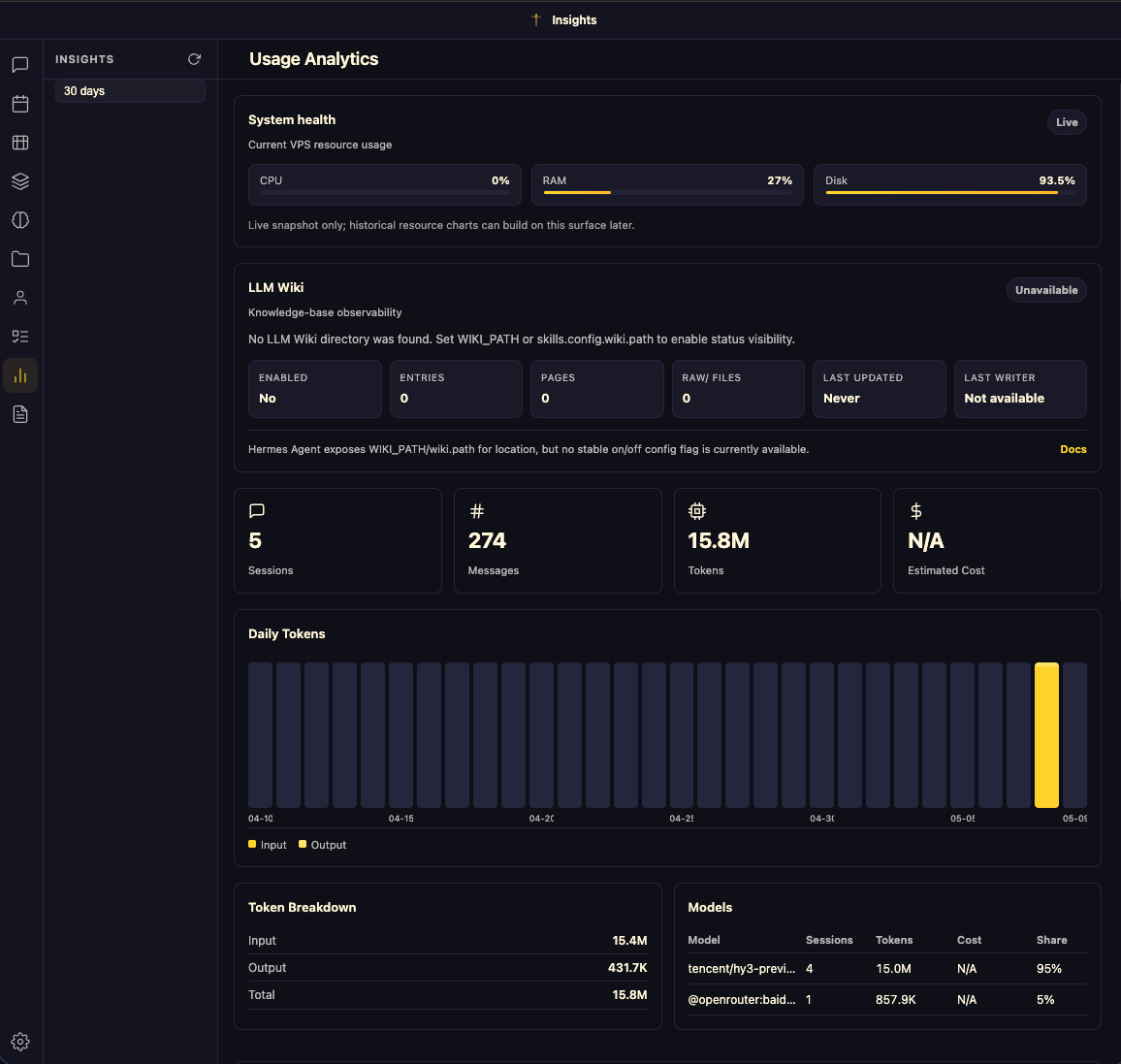
Oder der Hermes Agent ist auch ein gutes Beispiel. Gestern habe ich damit wieder herumgespielt und in der VM wo der Agent sitzt noch die Hermes WebUI installiert. Der braucht durch die Nutzung der Tools immer viele Token. Habe ihn dann gleich noch das smb Laufwerk in der VM einrichten lassen, so dass die WebUi das als Workspace nutze kann. Somit kann ich dort einfach mal Dateien ablegen, die er im Anschluss nutzen soll, bleibe aber in der VM. Hier mal die Auswertung von gestern aus der neuen WebUI.
15,8M sagt schon was!
Bin nicht mehr viel zum testen gekommen, mir ist mein Netzwerk im Carport auf einmal weg gewesen und musst mal auf die Suche gehen. Zur Zeit läuft es wieder aber wie lange ist die frage!
Sehr interessantes Video (um die Verwirrung komplett zu machen!![]() )
) ![]()

Die Anschaffungskosten sind hoch für Mac mit viel Speicher, aber die Stromkosten fast irrelevant. Mac Computer lässt man heutzutage meist einfach eingeschaltet. Dann haben sie alle cloud oder Email Daten topaktuell und die paar Watt verbrauchen interessieren typischerweise nicht.
Ich habe nur ein Mac mini M1 16 GB und träume von deinen 64GB.
Allerdings scheinen selbst die starken, lokalen Modelle, die man auf deinen 64 GB momentan laufen lassen könnte, immer noch eher für Spezialfälle geeignet zu sein. Also nicht wie bei Claude nach dem Motto: „mach mal“. Aber für klarer definierte Fälle sind die gemma4 oder die chinesischen Modelle um die 30B schon erstaunlich. Bilder analysieren, OCR, Emails parsen etc. geht schon ganz gut.
Ja das war damals (ist ja ein M1 und schon paar Jahre alt) eine gut Entscheidung! ![]()
Habe die letzten Jahre gedacht das das Teil „Lüfterlos“ sei, erst jetzt durch die KI Nutzung bringe ich den regelmäßig ins „Schwitzen“! ![]()
Und wenn ich sehe das der immer noch für fast 2k € gehandelt wird! Ok, hat auch mal 3,2k gekostet ist aber auch schon über 4 Jahre her!
Eigentlich wäre mal ein „neuer“ fällig, aber ich komme beim konfigurieren immer auf knapp 6k € ! ![]()
Trifft ja keinen Armen! ![]()
![]()
Da weißt du ja mehr als ich! ![]()
Da ich mein Geld in/mit „IT“ verdiene ist das mein Werkzeug „Nr.1“, da schaue ich eigentlich nicht auf jeden Euro, aber aktuell habe ich mich noch nicht dazu durchgerungen, erst mal abwarten ob es dieses Jahr noch neue „Macbooks pro“ geben wird!?