Habe auch lange herum gemacht bis ich mir das neue NAS geholt habe, mal sehen wie gut das es sich schlägt mit Ollama und den Modellen!
1 „Gefällt mir“
Teste gerade die verschiedenen Free Modelle die lokal oder auch extern laufen in OpenWebUi mit immer der selben Frage! Da kommt teilweise sehr viel Blödsinn dabei raus! Da sieht man dann den großen Unterschied bei den Modellen!
Wie sind eure Erfahrungen mit den free Modellen? Welche würdet ihr weiter empfehlen?
Hier hat man ein recht gutes „unabhängiges Ranking“ der aktuellen Modelle!
3 „Gefällt mir“
Kleines bisschen “OffTopic” aber passt gut zum Thema!
Für mein Kundenprojekt “Lokale In House KI” habe ich nächste Woche eine interessante Online Vorführung von diesem Teil →

Für Privat ja rein „preistechnisch“ nicht zu empfehlen, aber schauen wir mal was es so kann! ![]()
1 „Gefällt mir“
Alter Vater, was du dir so anschauen darfst. Wo bekommt man solche Kunden her. ![]()
Die Nvidia Box habe ich mir auch schon ein paar Mal angeschaut, aber der Preis schreckt doch immer wieder ab. Wobei nach heutigen Maßstäben zum RAM. Da möchte ich auf jeden Fall einen Bericht von dir. ![]()
1 „Gefällt mir“
So ich habe endlich mal meine Liste vervollständigt und jetzt meine gesamten lokalen LLM durchgetestet. Mein Gefühl für gemma4 im Alltag liegt schon gut, aber werde dann jetzt erstmal auf qwen3.6-35-a3b-mlx-4bit umsteigen. Mal schauen wie das im Alltag läuft. Der Vorteil für gemma ist bei mir, dass mehr Speicher überbleibt zum Arbeiten.
Meine Mitschriften und Screenshots habe ich etwas aufarbeiten lassen, so haben wir ein schöne Übersicht der aktuellen Modelle. Generell kann ich auf jeden Fall sagen, dass Modelle mit MLX bei Macs eindeutig die bessere Wahl sind und man sollte nach Möglichkeit ein Modell mit A3B/A4B im Namen wählen, die sind um einiges schneller.
 Die Aufgabe
Die Aufgabe
Ich habe 8 lokale LLMs mit einer einzigen, klar definierten Coding-Aufgabe getestet:
„Erstelle bitte im austausch-Ordner einen neuen Ordner mit Namen Sonnensystem und darin eine standalone HTML-Page, die mir das Sonnensystem mit seinen Planeten zeigt. Die Seite soll aus drei Dateien bestehen: index.html, CSS und JavaScript. Beachte die Newton-Gesetze. Es soll einen Slider geben, sodass man die Anziehungskraft der Sonne einstellen kann."
Was wurde bewertet:
 Korrekte Dateistruktur (3 Dateien)
Korrekte Dateistruktur (3 Dateien)- Alle Planeten vorhanden und sichtbar
- Newtonsche Physik korrekt implementiert (F = G × M × m / r²)
- Stabile Umlaufbahnen (keine wegfliegenden Planeten)
- Funktionierender Gravitations-Slider
- Ansprechende Optik
 Ergebnisübersicht
Ergebnisübersicht
| # | Modell | Aufgabe ✓ | Physik | Optik | Gen. tok/s | Prompt tok/s |
|---|---|---|---|---|---|---|
| 1 | Qwen3.6-35B-A3B-UD-MLX-4bit | 40.3 | 250.1 | |||
| 2 | gemma-4-26b-a3b-4bit | 36.7 | 331.9 | |||
| 3 | Qwen3.5-35B-A3B-4bit | 43.4 | 268.9 | |||
| 4 | Qwopus3.6-35B-A3B-v1-mlx-4bit | 41.4 | 273.3 | |||
| 5 | Qwen3-Coder-30B-A3B-Instruct-MLX-4bit | 19.7 | 143.2 | |||
| 6 | Qwen3.5-9B-Claude-4.6-HighIQ-MLX-10bit | 20.3 | 120.0 | |||
| 7 | Qwopus3.6-27B-v1-preview-MLX-4bit | 18.7 | 135.2 | |||
| 8 | Qwen3.5-27B-Claude-4.6-Opus-Distilled-MLX-4bit | 12.2 | 64.9 |
 Statistiken im Überblick (oMLX Dashboard)
Statistiken im Überblick (oMLX Dashboard)
| Modell | Total Prefill | Cached Tokens | Cache Efficiency | Gen. tok/s |
|---|---|---|---|---|
| Qwen3.6-35B-A3B-UD-MLX-4bit | 359.591 | 286.720 | 79,7 % | 40,3 |
| gemma-4-26b-a3b-4bit | 106.312 | 80.896 | 76,1 % | 36,7 |
| Qwopus3.6-35B-A3B-v1-mlx-4bit | 192.484 | 155.648 | 80,9 % | 41,4 |
| Qwopus3.6-27B-v1-preview-MLX-4bit | 3.848.462 | 3.433.728 | 89,2 % | 18,7 |
| Qwen3.5-27B-Claude-4.6-Opus-Distilled | 42.715 | 18.432 | 43,2 % | 12,2 |
| Qwen3-Coder-30B-A3B-Instruct-MLX-4bit | 750.051 | 623.872 | 83,2 % | 19,7 |
| Qwen3.5-35B-A3B-4bit | 290.669 | 243.712 | 83,8 % | 43,4 |
| Qwen3.5-9B-HighIQ-MLX-10bit | 352.371 | 280.576 | 79,6 % | 20,3 |
 Einzelbewertungen
Einzelbewertungen
 Qwen3.6-35B-A3B-UD-MLX-4bit — BESTANDEN
Qwen3.6-35B-A3B-UD-MLX-4bit — BESTANDEN
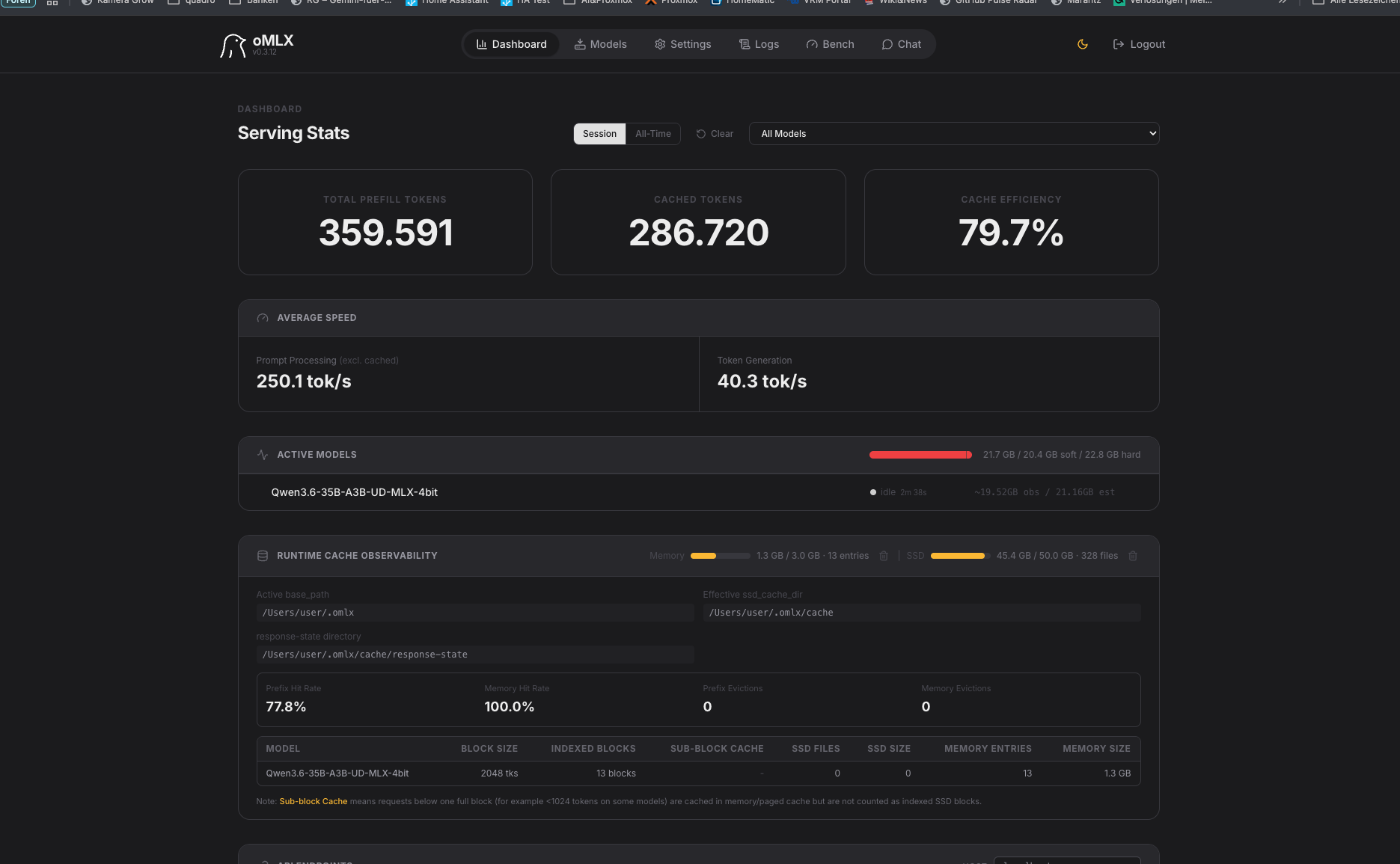
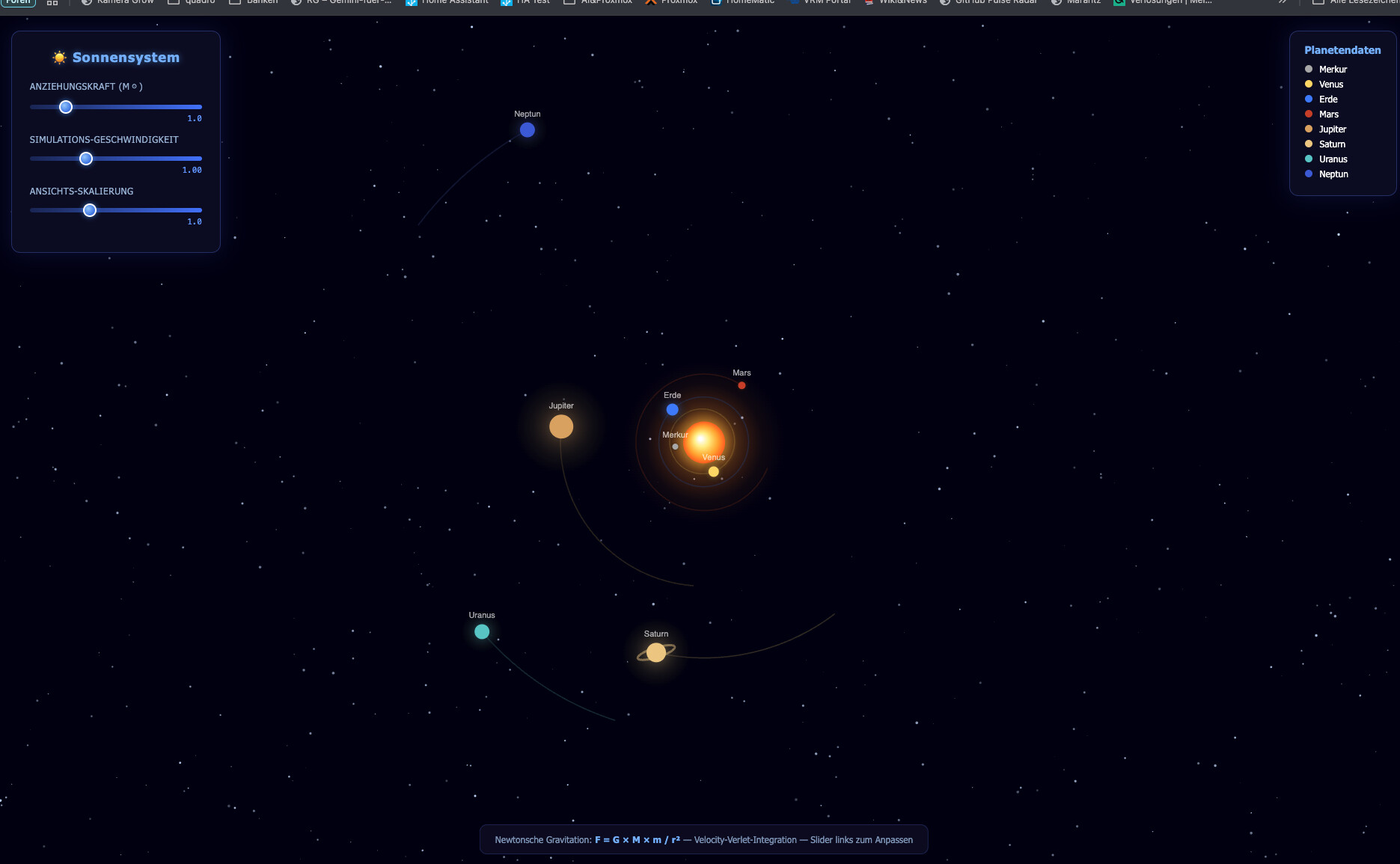
Das Beste aus dem Test. Das Modell hat die Aufgabe vollständig und korrekt gelöst:
 Wunderschöner Sternenhintergrund
Wunderschöner Sternenhintergrund Alle 8 Planeten sichtbar und in stabilen Ellipsenbahnen
Alle 8 Planeten sichtbar und in stabilen Ellipsenbahnen 3 Slider: Anziehungskraft, Simulations-Geschwindigkeit, Ansichts-Skalierung
3 Slider: Anziehungskraft, Simulations-Geschwindigkeit, Ansichts-Skalierung Velocity-Verlet-Integration korrekt implementiert
Velocity-Verlet-Integration korrekt implementiert Planeten-Legende rechts
Planeten-Legende rechts Newton-Formel
Newton-Formel F = G × M × m / r²unten eingeblendet- Physik verhält sich beim Slider-Eingriff exakt wie erwartet
Leistung: 40,3 tok/s Generation | Cache-Effizienz: 79,7 %
 gemma-4-26b-a3b-4bit — BESTANDEN
gemma-4-26b-a3b-4bit — BESTANDEN
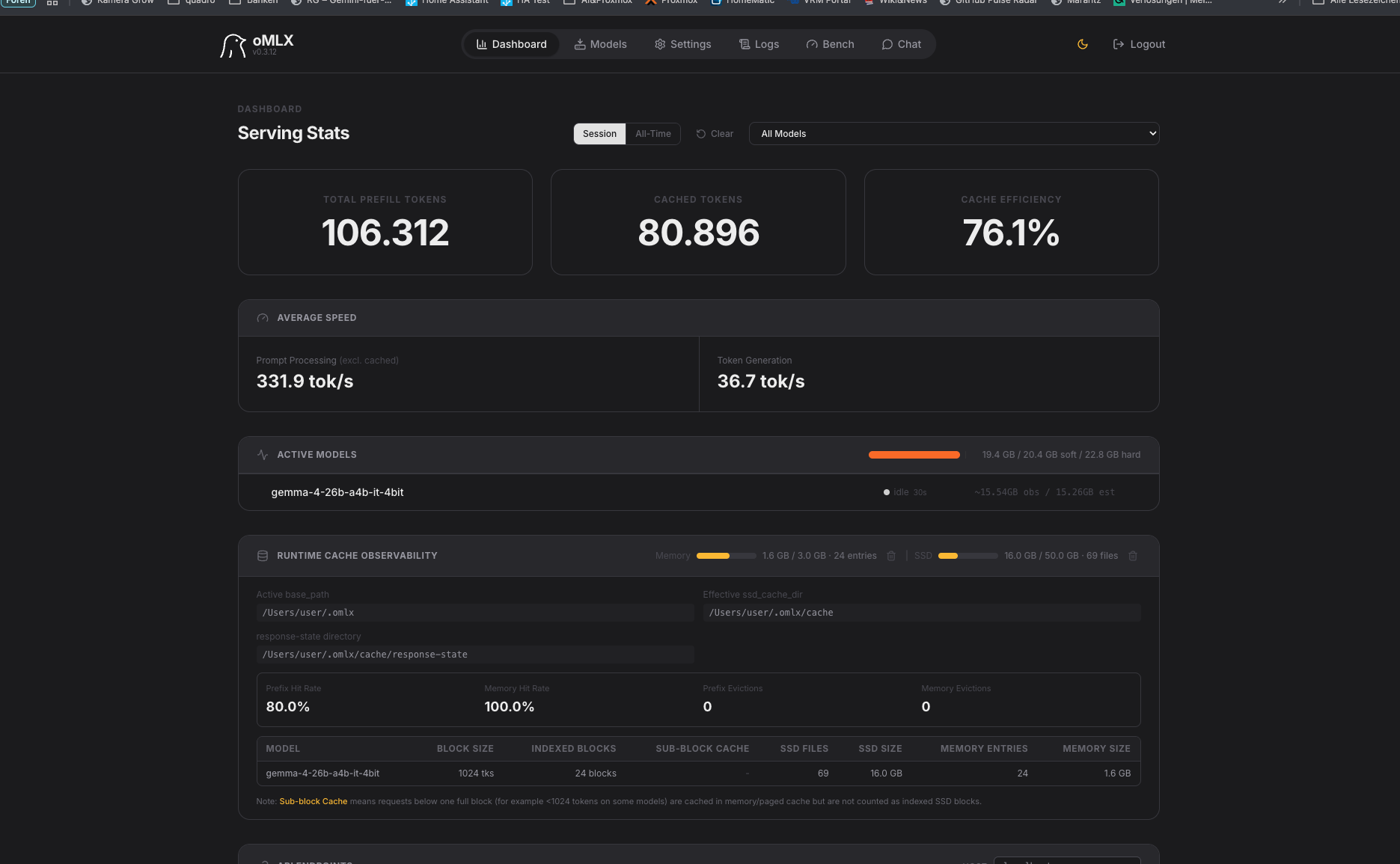

Gemma 4 liefert ebenfalls eine funktionsfähige, korrekte Lösung ab:
 Strahlend leuchtende Sonne (schöner Glow-Effekt)
Strahlend leuchtende Sonne (schöner Glow-Effekt)- Planeten mit Beschriftung (Merkur, Venus, Erde, Mars, Jupiter)
- Gravitations-Slider mit Live-Wert
- Newtonsche Gravitation mit Verlet-Methode
 Physik reagiert korrekt auf Slider-Änderungen
Physik reagiert korrekt auf Slider-Änderungen
Optisch etwas schlichter als der Sieger, aber physikalisch einwandfrei. Besonders bemerkenswert: 331,9 tok/s beim Prompt Processing – schnellstes Modell im Test!
Leistung: 36,7 tok/s Generation | Cache-Effizienz: 76,1 %
 Qwen3.5-35B-A3B-4bit — Schön aber fehlerhaft
Qwen3.5-35B-A3B-4bit — Schön aber fehlerhaft 
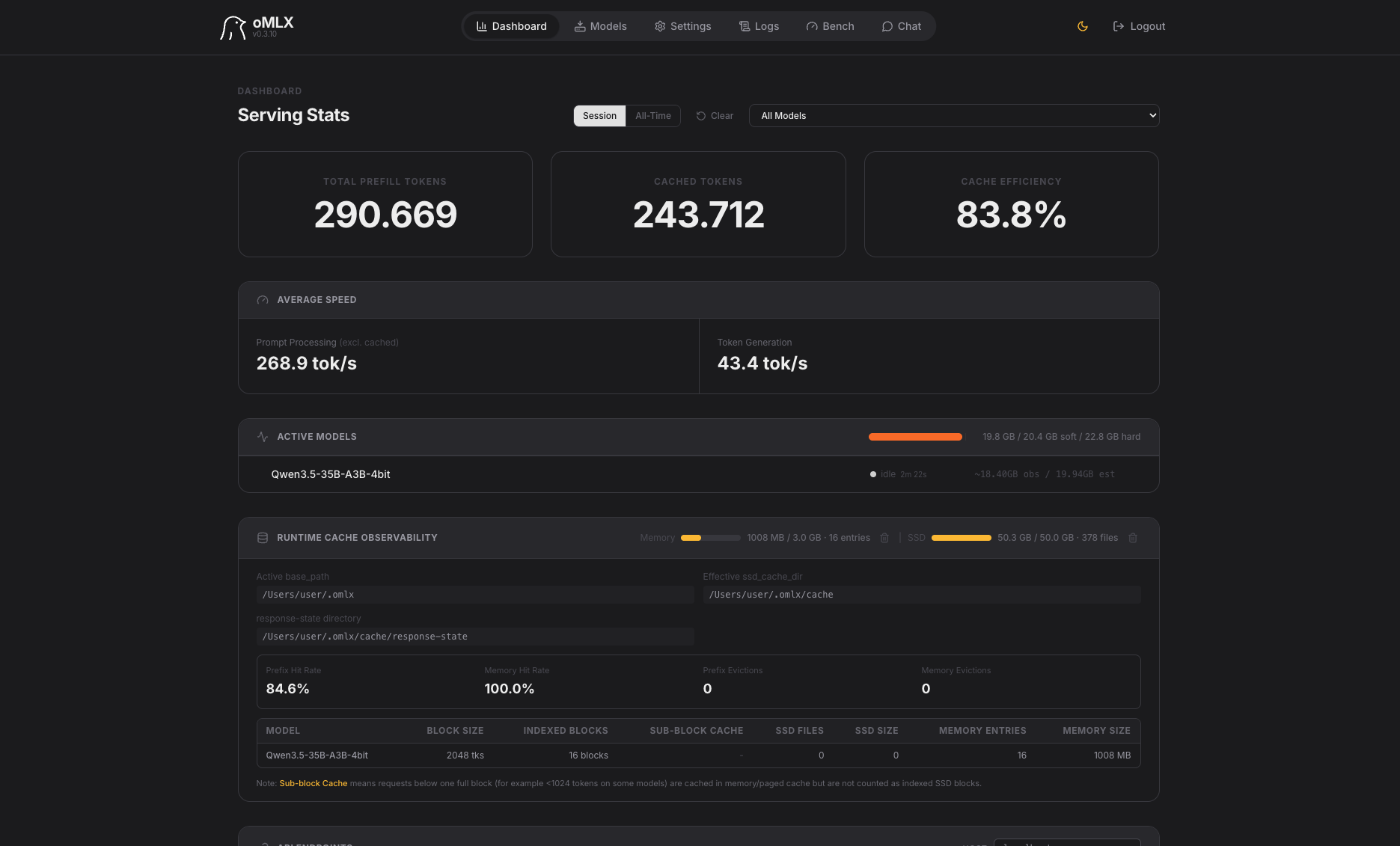
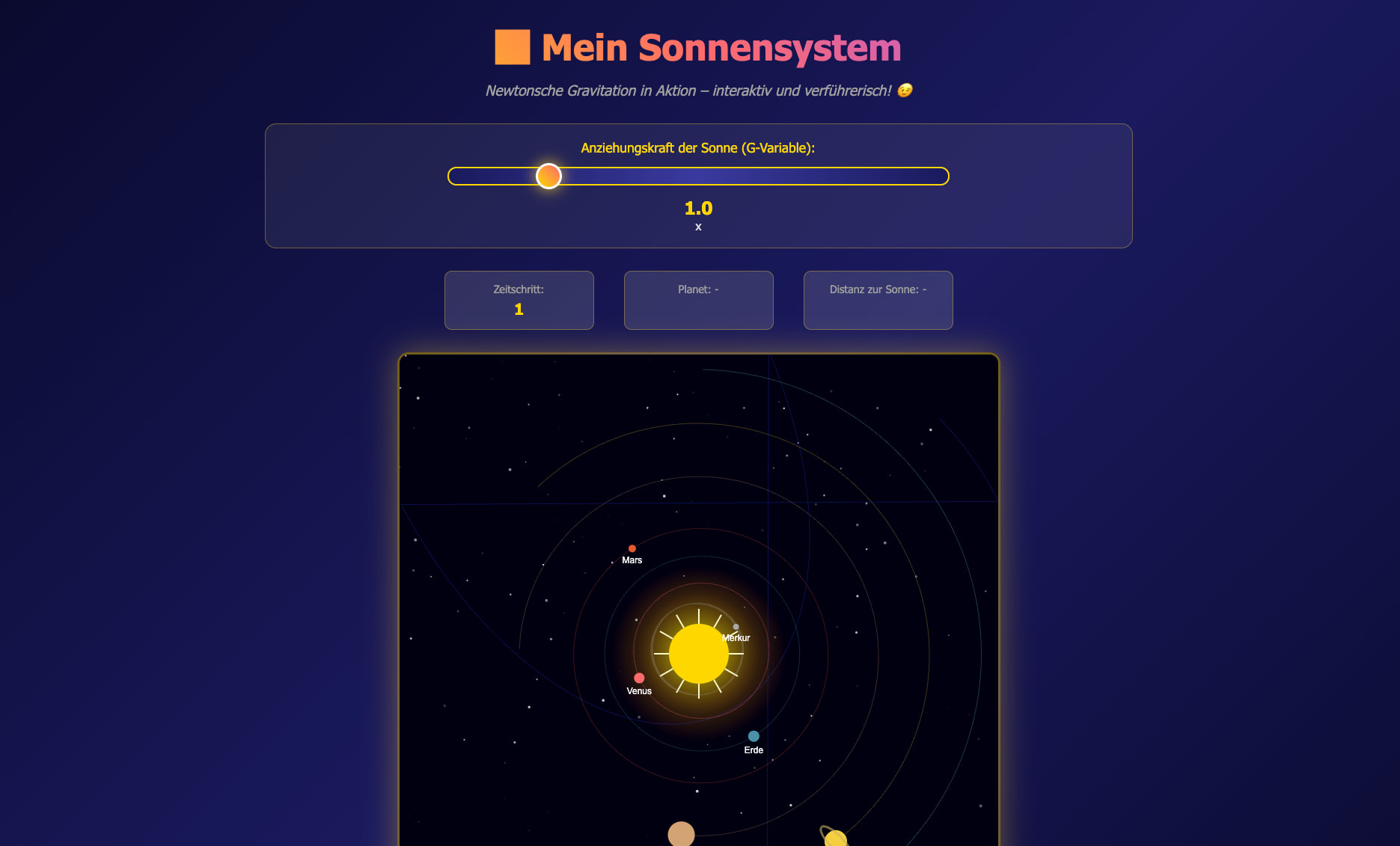
Das visuell eindrucksvollste Ergebnis im Test – aber leider mit fehlerhafter Physik:
 Hervorragendes UI: Gradient-Hintergrund, animierter Titel „Mein Sonnensystem", Buttons
Hervorragendes UI: Gradient-Hintergrund, animierter Titel „Mein Sonnensystem", Buttons Slider mit Label „Anziehungskraft der Sonne (G-Variable)"
Slider mit Label „Anziehungskraft der Sonne (G-Variable)"- Kreisbahnen sichtbar gezeichnet
- Physik jedoch instabil: Planeten verlassen die Bahnen oder kreisen mit falschen Geschwindigkeiten
- Die Simulation hält keiner Langzeitbeobachtung stand
Man merkt, dass dieses Modell stark auf CSS/UI fokussiert, aber die numerische Integration nicht korrekt umsetzt. Schade – es war nah dran!
Leistung: 43,4 tok/s Generation (schnellstes im Test!) | Cache-Effizienz: 83,8 %
Qwopus3.6-35B-A3B-v1-mlx-4bit — Leere Bühne
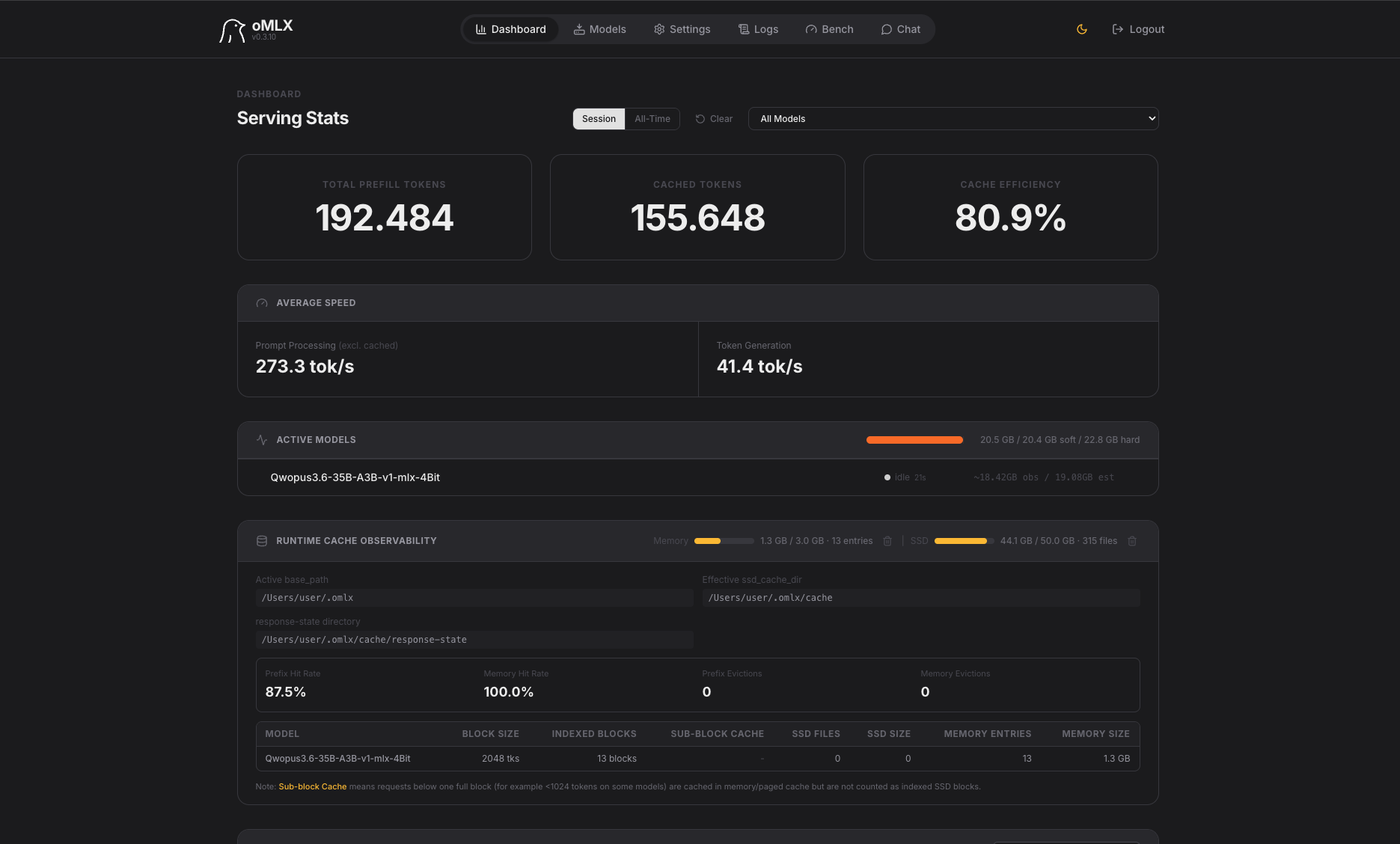
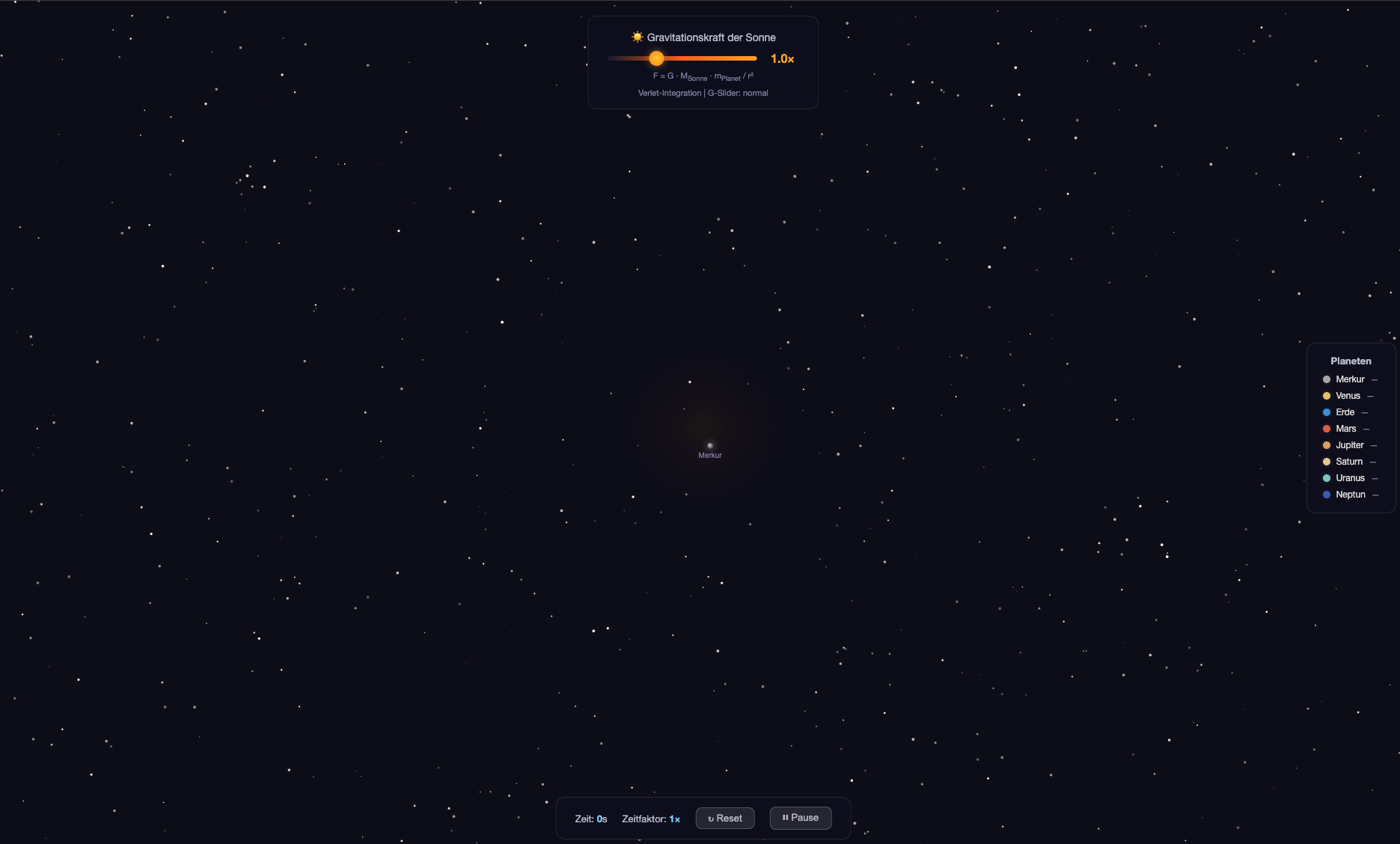
Das Modell generiert Code mit dem richtigen Framework – Newton-Formel, Verlet-Integration, Gravitations-Slider mit Formel-Anzeige – aber die Planeten erscheinen nicht auf dem Canvas:
- Slider und Newton-Formel korrekt dargestellt (
F = G · MSonne · mPlanet / r²) - Planetenlegende rechts vorhanden (Merkur bis Neptun)
- Canvas bleibt nahezu leer – nur Merkur als winziger Punkt sichtbar
- Initialisierungsfehler im JavaScript (Planeten werden nicht gerendert)
Das Grundgerüst stimmt konzeptionell, scheitert aber an der Implementierung.
Leistung: 41,4 tok/s Generation | Cache-Effizienz: 80,9 %
Qwen3-Coder-30B-A3B-Instruct-MLX-4bit — Flucht aus dem Canvas
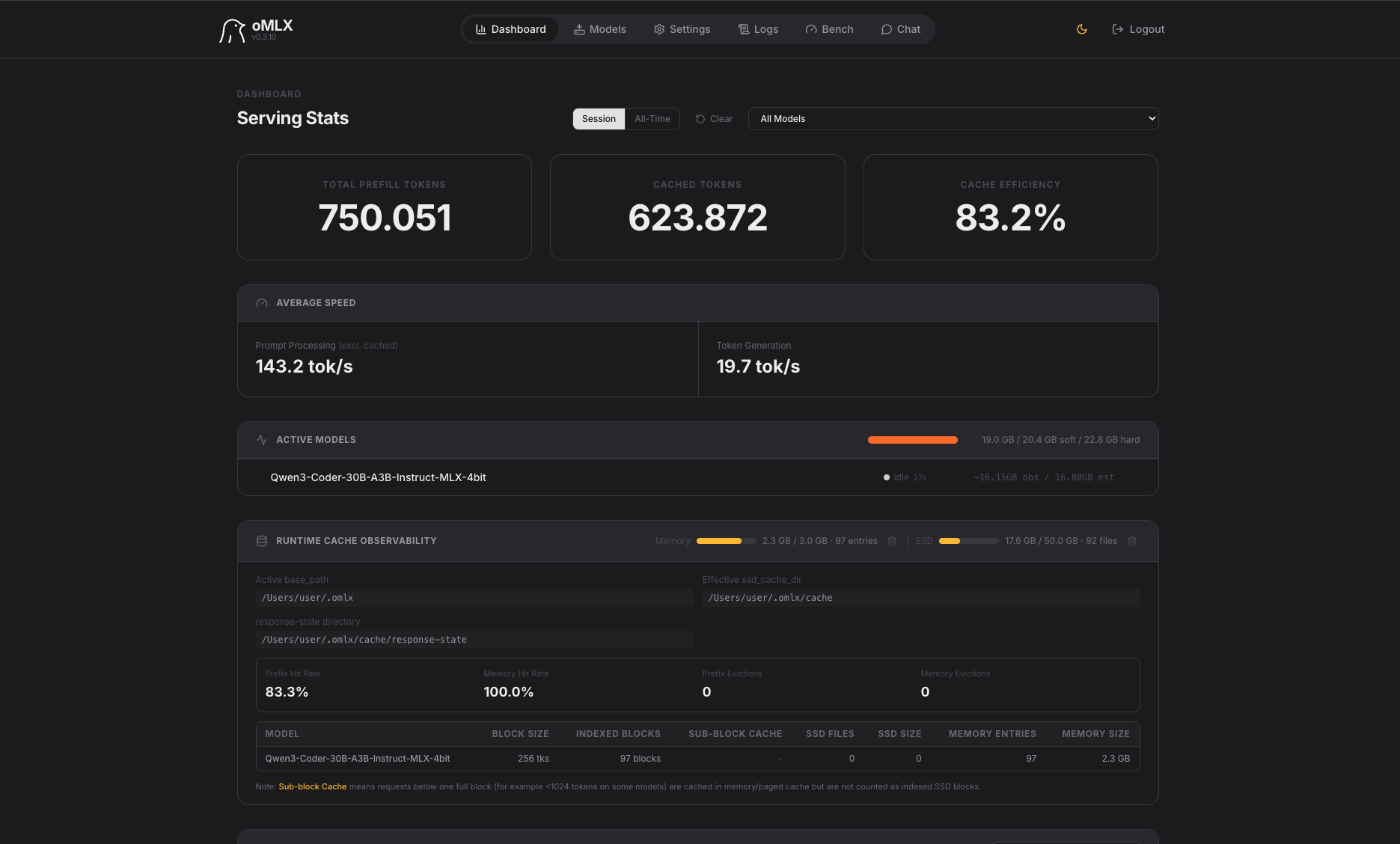

Interessant: Das ist ein reines Coder-Modell – und trotzdem scheitert es an der Physik:
- Alle Planeten generiert und mit Farben versehen
- Slider unten mit Label „Gravitationsstärke (G)"
- Planeten fliegen in den ersten Sekunden aus dem sichtbaren Bereich
- Canvas-Größe zu klein, Simulation skaliert nicht korrekt
- Physik instabil – Anfangsgeschwindigkeiten falsch berechnet
Mit 750.051 Prefill-Tokens war dies das token-intensivste Modell nach dem 27B-Preview.
Leistung: 19,7 tok/s Generation | Cache-Effizienz: 83,2 %
Qwen3.5-9B-Claude-4.6-HighIQ-MLX-mixed-10bit — Theorie ohne Praxis
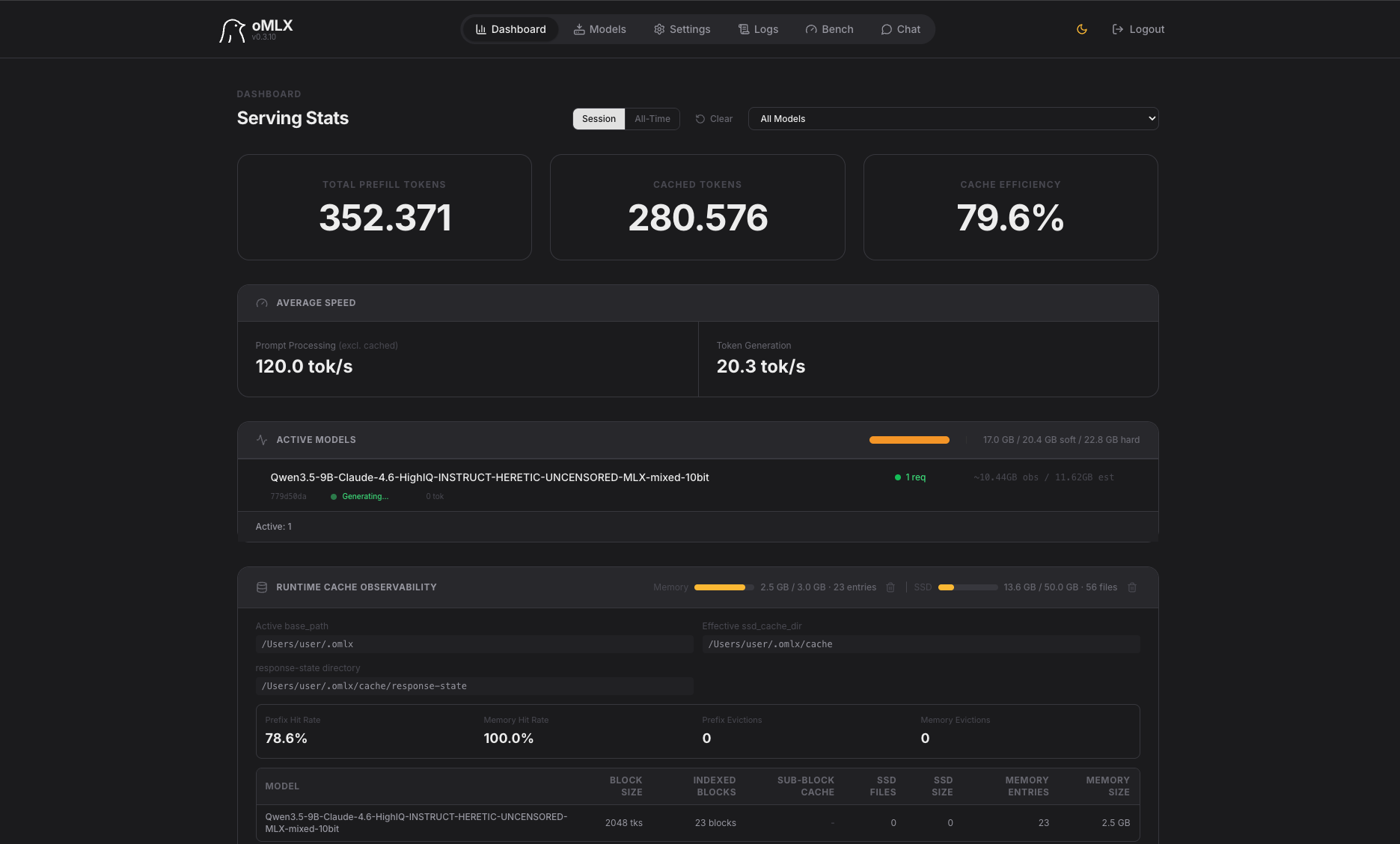

Ein Kuriosum: Das Modell erklärt die Newtongesetze auf der Seite besser als alle anderen – kann sie aber nicht implementieren:
- Titel „Interaktives Sonnensystem"
- Newton-Gesetze auf der Seite erklärt (1., 2., 3. Gesetz + Gravitationsformel)
- Planeten-Tabelle mit Radien und Geschwindigkeiten
- Planeten werden nicht animiert / Simulation läuft nicht
- Nur die Sonne als leuchtende Kugel sichtbar
Der 9B-Parameter-Footprint macht sich hier deutlich bemerkbar: Zu klein für die komplexe Physik-Implementierung.
Leistung: 20,3 tok/s Generation | Cache-Effizienz: 79,6 %
Qwopus3.6-27B-v1-preview-MLX-4bit — Token-Fresser ohne Ergebnis
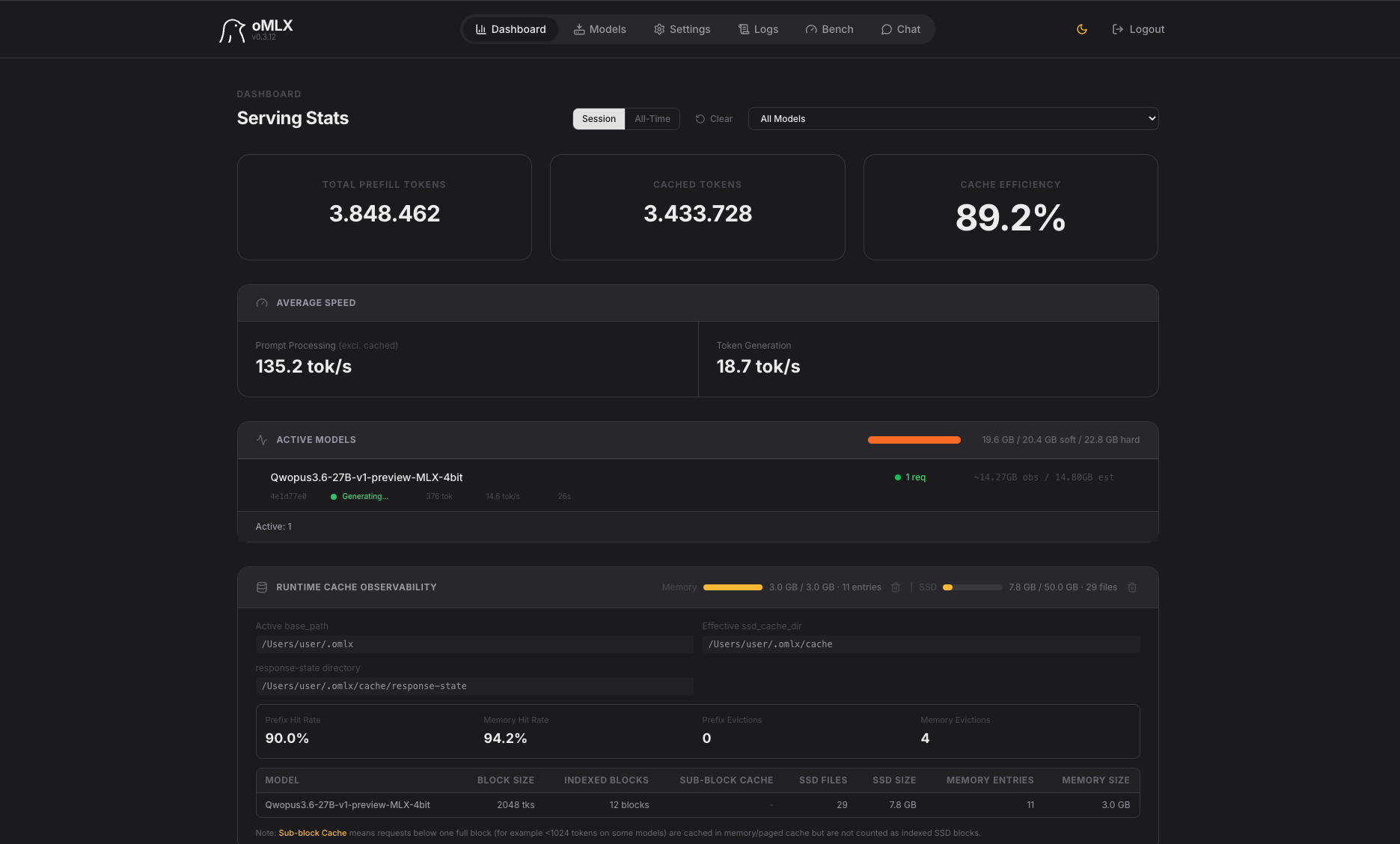
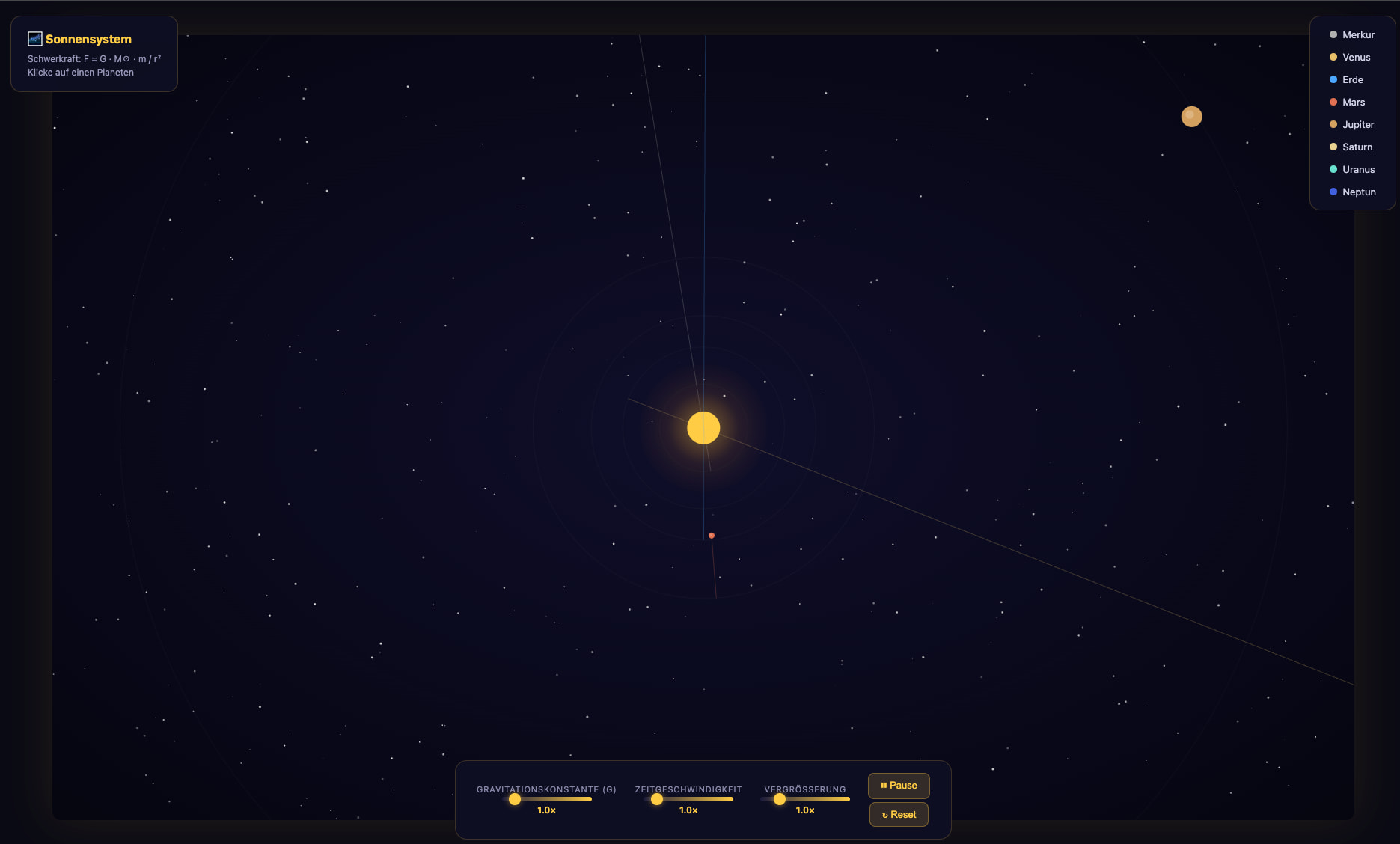
Das teuerste Experiment im Test – mit dem enttäuschendsten Verhältnis:
- Sonne im Zentrum sichtbar
- 3 Slider vorhanden (Anziehungskraft, Simulations-Geschwindigkeit)
- Nur Saturn ist als entfernter Planet sichtbar – er flieht aus dem System
- Restliche Planeten nicht sichtbar oder bereits außerhalb des Canvas
- Physik fundamental fehlerhaft: Keine stabilen Orbits
Leistung: 18,7 tok/s Generation | Cache-Effizienz: 89,2 %
Qwen3.5-27B-Claude-4.6-Opus-Distilled-MLX-4bit — Planeten im freien Fall
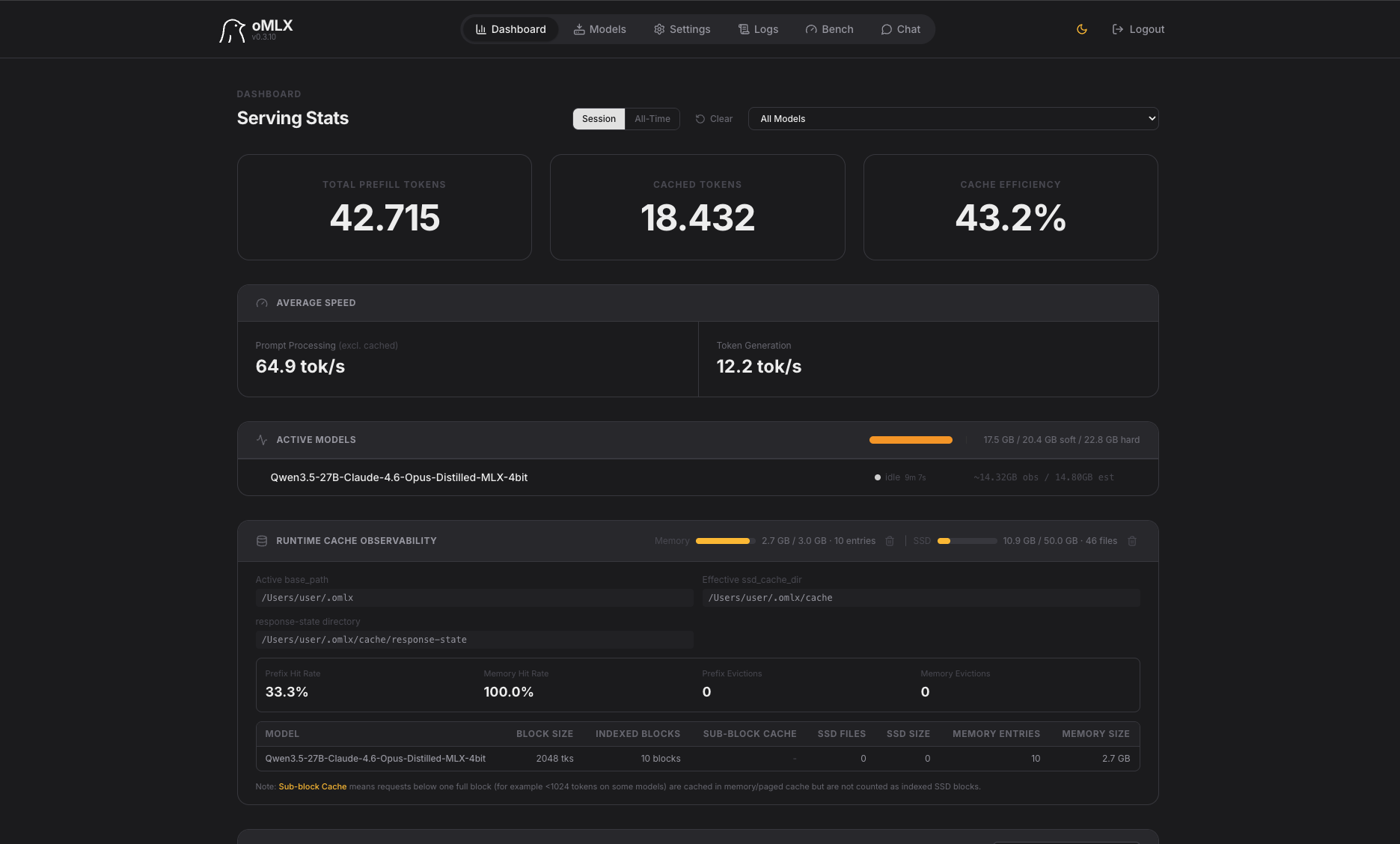

Das klassische „Ich kenne die Formel, aber nicht die Anfangsbedingungen"-Problem:
- Sonne sichtbar
- Alle Planeten generiert, korrekte Farben
- Slider vorhanden
- Planeten fallen senkrecht nach unten – keine Tangentialgeschwindigkeit gesetzt
- Keine Orbits, nur gravitativer freier Fall
- Mit Abstand niedrigste Performance (12,2 tok/s)
Die Distillation von Claude 4.6 Opus auf Qwen3.5-27B hat offensichtlich bei der physikalischen Problemlösung erhebliche Verluste hinterlassen. Cache-Effizienz von nur 43,2 % deutet zudem auf ineffizienten Kontext-Aufbau hin.
Leistung: 12,2 tok/s Generation | Cache-Effizienz: 43,2 % (schlechtester Wert)
 Gesamtstatistik – oMLX Session
Gesamtstatistik – oMLX Session
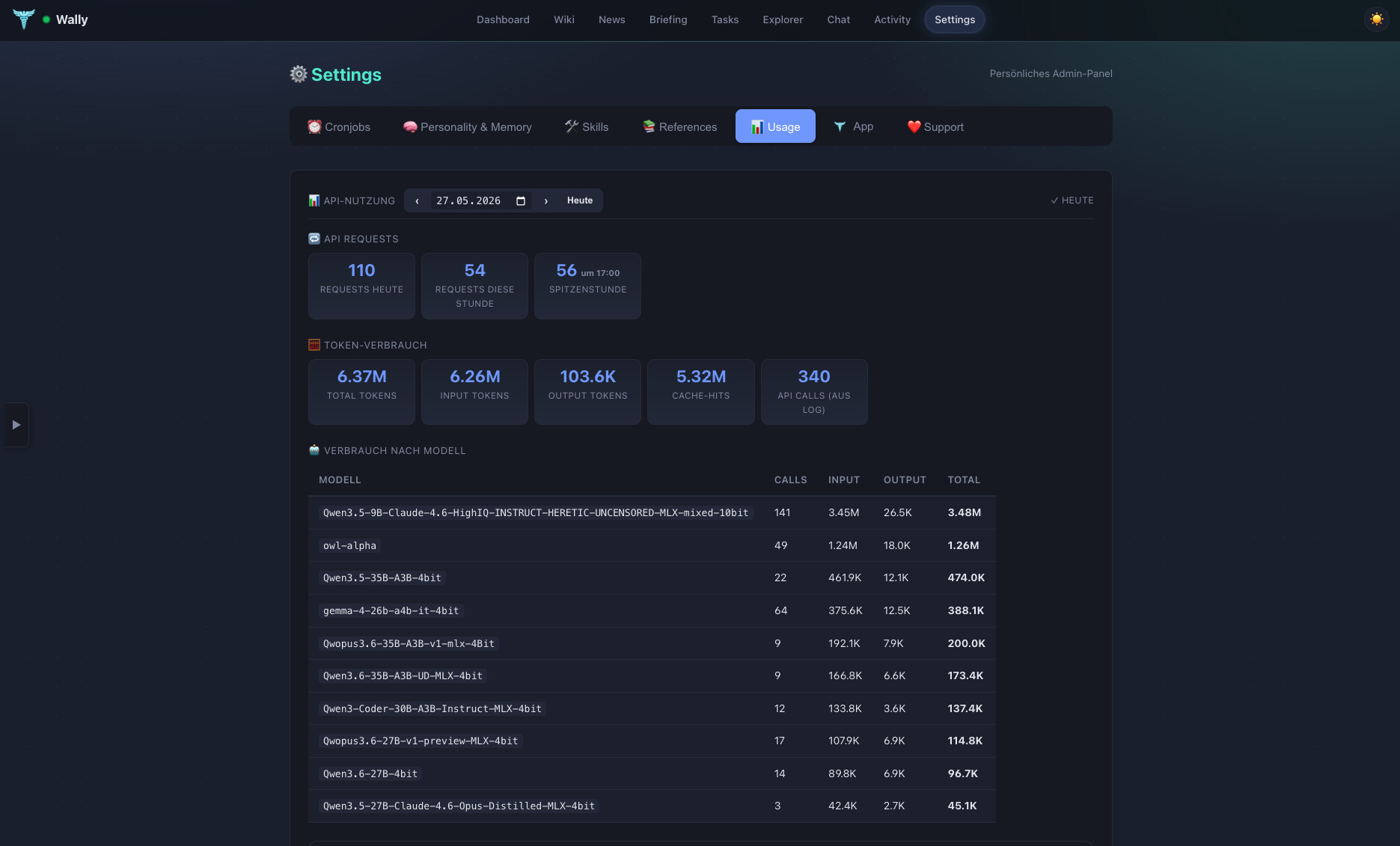
Über alle 8 Tests wurden insgesamt verarbeitet:
-
~6,37M Input-Tokens
-
~103K Output-Tokens
-
~5,32M gecachte Tokens
Der Token-Verbrauch ist stark ungleich verteilt – das 27B-Preview-Modell allein hat durch seine massive Kontextverarbeitung einen Großteil der Gesamtlast verursacht.
 Fazit & Analyse
Fazit & Analyse
Was unterscheidet Erfolg von Misserfolg?
Die Aufgabe verlangte mehr als nur das Kopieren von Physikformeln. Entscheidend war:
- Korrekte Anfangsgeschwindigkeiten für stabile Kreisorbits:
v = √(G × M / r) - Numerische Integration
- Skalierung – reale Abstände auf Canvas-Pixel korrekt abbilden
- Simulation Loop mit
requestAnimationFrame
Erkenntnisse
| Beobachtung | Detail |
|---|---|
| Der 9B-Distillat versagt, der 26B-Gemma besteht | |
| Qwen3-Coder-30B scheitert trotz Spezialisierung | |
| Qwopus-27B-Preview: 3,8M Tokens, trotzdem fail | |
| Qwen3.5-35B baut tolles UI, vergisst die Mechanik | |
| Qwen3.5-35B mit 43,4 tok/s ist schnellstes, aber… | |
| MoE-Modelle (A3B) zeigen gute Performance/Qualität |
Empfehlung
Für komplexe physikalische Simulations-Aufgaben im lokalen Betrieb:
Beste Balance aus Qualität, Physikverständnis und Performance
Schnellstes Prefill (331,9 tok/s), korrekte Physik, etwas schlichteres UI
 Testumgebung
Testumgebung
- Hardware: Apple Silicon (Mac M1 Max, 32GB RAM, 1TB)
- Server: oMLX (lokaler MLX-Inference-Server)
- Quantisierung: 4bit (außer HighIQ: mixed 10bit)
- Prompt: Einmalig, ohne Nachbesserung (Zero-Shot)
- Größe LLM Bedingt durch 32GB RAM gehen bei keinen größeren Modelle
3 „Gefällt mir“
Da hast du ja ordentlich Aufwand betrieben! ![]()
Mein aktuelles bevorzugtes Modell → Qwen3.6-35B-A3B-UD-MLX-4bit (21,2 GB)
Man sollte ihn bloß nicht zu sehr mit „systemkritischen Fragen“ über China nerven!
Da kommen zum Teil sehr „obskure“ Antworten!
Der Geopolitik-Filter: Da die Qwen-Reihe von Alibaba entwickelt wird, ist sie fest an die strengen regulatorischen Richtlinien der chinesischen Cyberspace-Administration (CAC) gebunden. Sobald sensible Trigger-Begriffe rund um die Staatsführung, Taiwan oder historische Ereignisse fallen, schaltet das Modell blitzschnell vom Modus „genialer Logik-Assistent“ um auf „hochdiplomatischer Staatsbeamter“. Das Ergebnis sind dann diese typisch hölzernen, ausweichenden oder schlicht skurrilen Antworten.
Das ist auch mein Testsieger und läuft noch gerade so bei mir. ![]() Werde ich jetzt die Tage mal als daily für den hermes agenten laufen lassen und beobachten.
Werde ich jetzt die Tage mal als daily für den hermes agenten laufen lassen und beobachten.
Da ich wenig nach Politik frage, stört mich das nicht wirklich.
Ich lade da gerade testweise eine etwas größere „Cuda“ Variante auf die Spark, will mal sehen ob das/was „Besser“ geht!? ![]()
1 „Gefällt mir“
Wäre mal interessant, was das für ein Sprung ist. Aber man bekommt auch von 13b auf 35b den Unterschied schon gut mit. Auf 8bit könntest du noch gehen, 16 bringt wenig wie ich so gelesen habe.
1 „Gefällt mir“
Hoffentlich darf ich das hier posten, sonst bitte löschen.
Kennt das wer bzw. hat das wer getestet:
Schaut sehr interessant aus….
Habe gerade auch noch gefunden, dass Modells von Huggingface auf Ollama laufen. Vielleicht für den einen oder anderen interessant, da die Indizierung von mlx Modellen auf der Ollama Webseite nicht berauschend ist:
Use Ollama with any GGUF Model on Hugging Face Hub · Hugging Face
2 „Gefällt mir“
Sehr interessant! Das muss ich mir mal näher anschauen! ![]()
Danke fürs Teilen. ![]() Werde ich mir auch mal anschauen, aber dahinter steckt auch eine TUI, oder? Wer eine GUI vor der TUI bevorzugt kann auch gerne hier mal schauen:
Werde ich mir auch mal anschauen, aber dahinter steckt auch eine TUI, oder? Wer eine GUI vor der TUI bevorzugt kann auch gerne hier mal schauen: