Wir hatten diese Woche ein sehr interessantes Wochenthema. Vielen Dank an @Dreckfresse für den Input. Ich wollte nicht, dass dieses Thema untergeht und habe daher ein kleines Wiki inkl. Analyzer Tool geschrieben in der Hoffnung, dass hier viele mitlesen und es nutzen können.
Man kann wie im HA-Forum beschrieben wurde, auf dem Dahsboard einen Button anlegen, der nach drücken alle Home Assistant Entitäten, Automationen usw. in eine csv Datei exportiert. Diese Funktion vermisse ich aktuell in HA, da man so eine schöne “offline/backup” Variante hat, die Entitäten für sich zu strukturieren, zu kontrollieren, zu dokumentieren bzw. sich einen Überblick zu verschaffen. Perfekt um “Leichen” auszusortieren, Namenstrukturen zu entwickeln usw.. Anschauen könnt ihr euch die csv-Datei z.B. mit dem beigefügtem Analyzer Tool oder mit Excel.

Erstellt als erstes im Dashboard eine neue custom button card und fügt dort folgenden Code ein. Im Anschluss solltet ihr wie im Bild gezeigt diesen Button erhalten. Drückt nach Fertigstellung den Button und ihr bekommt die csv-Datei in den Download-Ordner.
type: custom:button-card
name: Entity Export as CSV2
tap_action:
action: javascript
javascript: |
[[[
function clean(value) {
if (!value) return "";
return String(value)
.replace(/;/g, ",")
.replace(/\r?\n|\r/g, " ");
}
async function generateCSV() {
const hass = document.querySelector("home-assistant").hass;
const areas = await hass.callWS({ type: "config/area_registry/list" });
const devices = await hass.callWS({ type: "config/device_registry/list" });
const entities = await hass.callWS({ type: "config/entity_registry/list" });
const areaLookup = {};
areas.forEach(a => (areaLookup[a.area_id] = a.name));
let csv =
"ENTITY ID;ENTITY NAME;DEVICE NAME;DEVICE ID;AREA;PLATFORM;STATE;FORMATTED STATE;" +
"MANUFACTURER;MODEL;MODEL ID;SW VERSION;HW VERSION\n";
Object.values(hass.states)
.sort((a, b) => a.entity_id.localeCompare(b.entity_id))
.forEach(stateObj => {
const entReg = entities.find(e => e.entity_id === stateObj.entity_id);
const device = devices.find(d => d.id === entReg?.device_id);
const areaName =
entReg?.area_id
? areaLookup[entReg.area_id] || ""
: device?.area_id
? areaLookup[device.area_id] || ""
: "";
// Plattform
const platform =
entReg?.platform ||
entReg?.integration ||
stateObj.entity_id.split(".")[0];
// Geräteattribute
const manufacturer = device?.manufacturer || "";
const model = device?.model || "";
const model_id = device?.model_id || "";
const sw_version = device?.sw_version || "";
const hw_version = device?.hw_version || "";
const row = [
clean(stateObj.entity_id),
clean(hass.formatEntityName(stateObj)),
clean(device?.name || ""),
clean(entReg?.device_id || ""),
clean(areaName),
clean(platform),
clean(stateObj.state),
clean(hass.formatEntityState(stateObj)),
clean(manufacturer),
clean(model),
clean(model_id),
clean(sw_version),
clean(hw_version)
].join("; ");
csv += row + "\n";
});
const blob = new Blob([csv], { type: "text/csv;charset=utf-8;" });
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = "hass_entities.csv";
a.click();
URL.revokeObjectURL(url);
}
generateCSV();
]]]

Für Windows, Mac oder Linux ladet euch einfach die ausführbare Version herunter und startet das Programm.
Hier könnt ihr das Tool bei mir im github herunterladen:
Betrifft nur die manuelle Installation:
Das Tool nutzt Python, daher muss Python installiert sein oder werden!
In Windows öffnet ihr dazu die Powershell und gebt folgenden Befehl ein:
winget install Python
Alternativ oder sogar besser ist es die aktuelle Python-Version von der Website für Windows herunterzuladen und zu installieren.
Danach installiert ihr noch das pandas Paket bzw. die Bibliothek:
pip install pandas
Unter Windows könnt ihr die Python Datei direkt aus dem „src“ Ordner mit Doppelklick starten.
Unter Linux gebt folgende Befehle im Terminal ein:
sudo apt update && sudo apt install python3
Danach installiert ihr noch das pandas Paket bzw. die Bibliothek:
pip install pandas
Um das Programm zu öffnen, wechselt mit cd /euer Verzeichnis in den Ordner wo euer Entity_Analyzer liegt und startet mit folgendem Befehl das Tool.
python3 entity_analyzer_v1.py
Nun könnt ihr den Entity_Analyzer öffnen und eure csv-Datei auswählen. Die Oberfläche bietet ein paar Möglichkeiten eure Entitäten zu sichten. Nach dem öffnen seht ihr unten links die Anzahl der Entitäten!
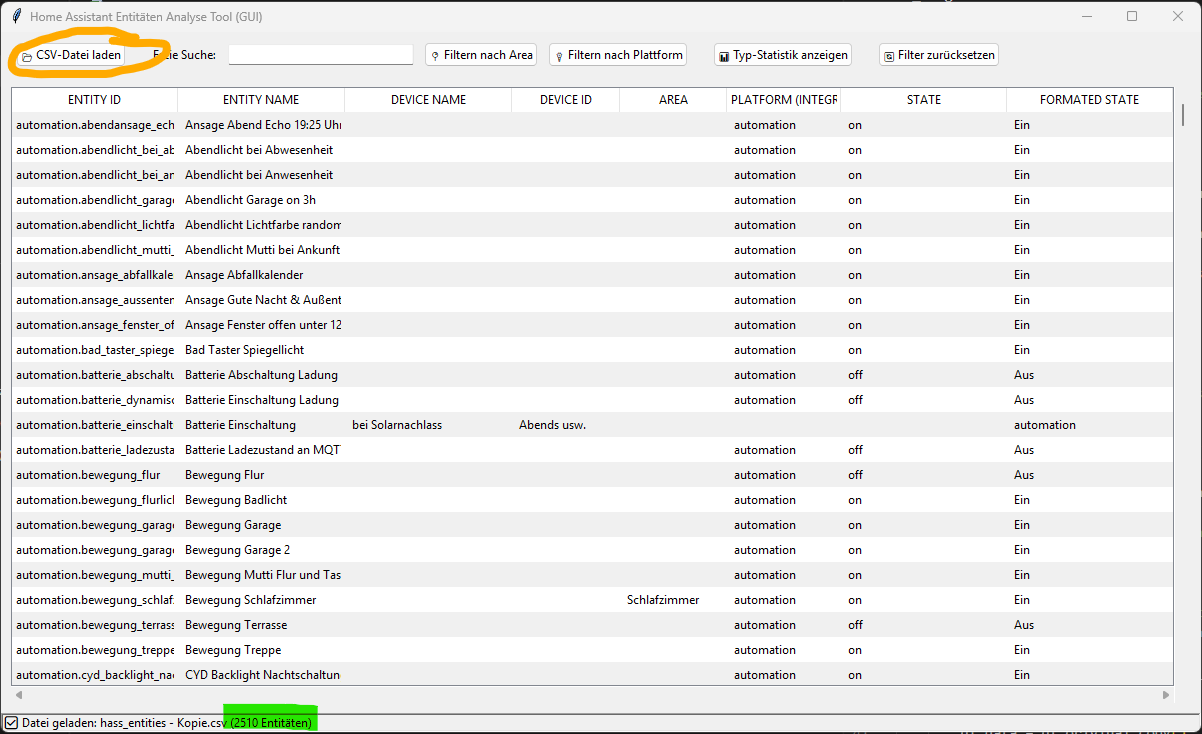
-
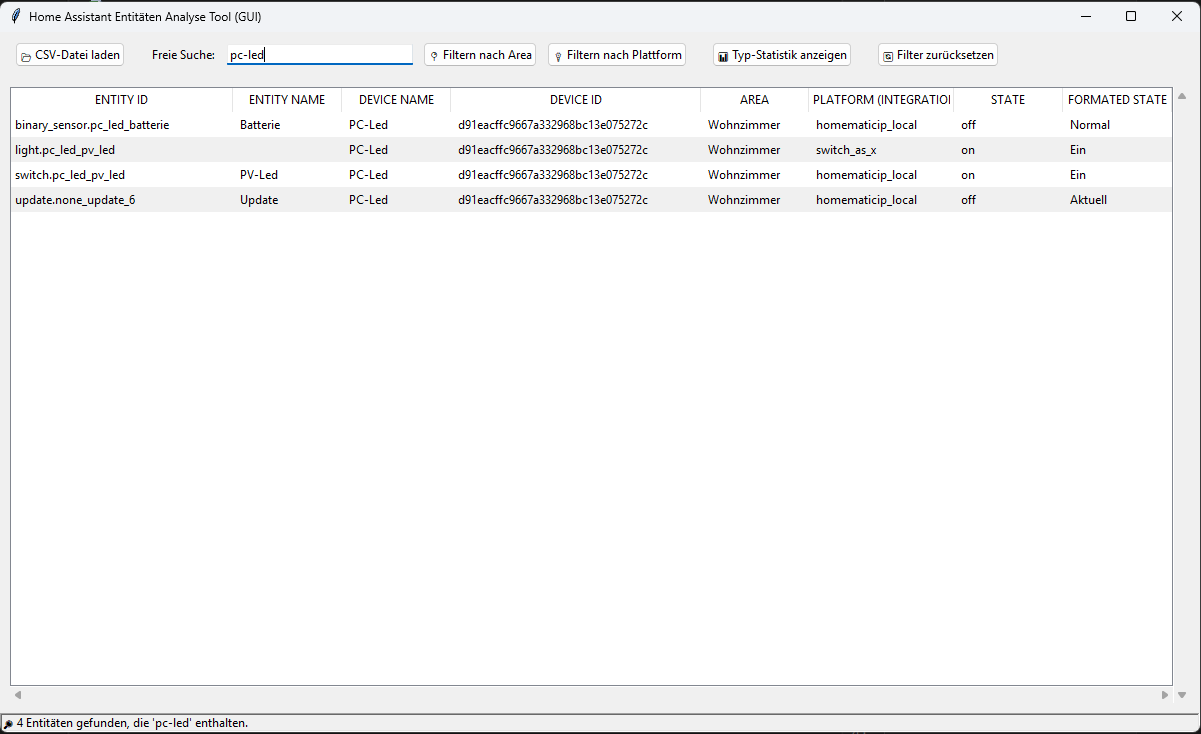
Jetzt könnt ihr beispielsweise nach gewünschten Entitäten suchen:
Über die Spaltennamen kann beim auswählen eine aufsteigende oder absteigende Sortierung erfolgen.
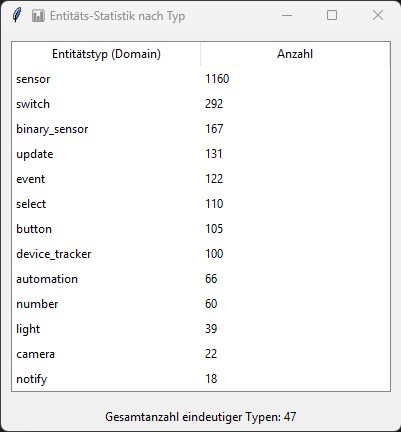
- Die Entitätsstatistik abrufen und sehen wie viele Lichter oder Schalter ihr habt usw.:
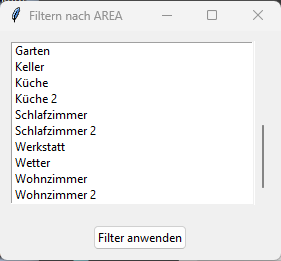
- Oder ihr könnt nach Area also Bereichen bzw. nach Platform und somit Integrationen filtern.
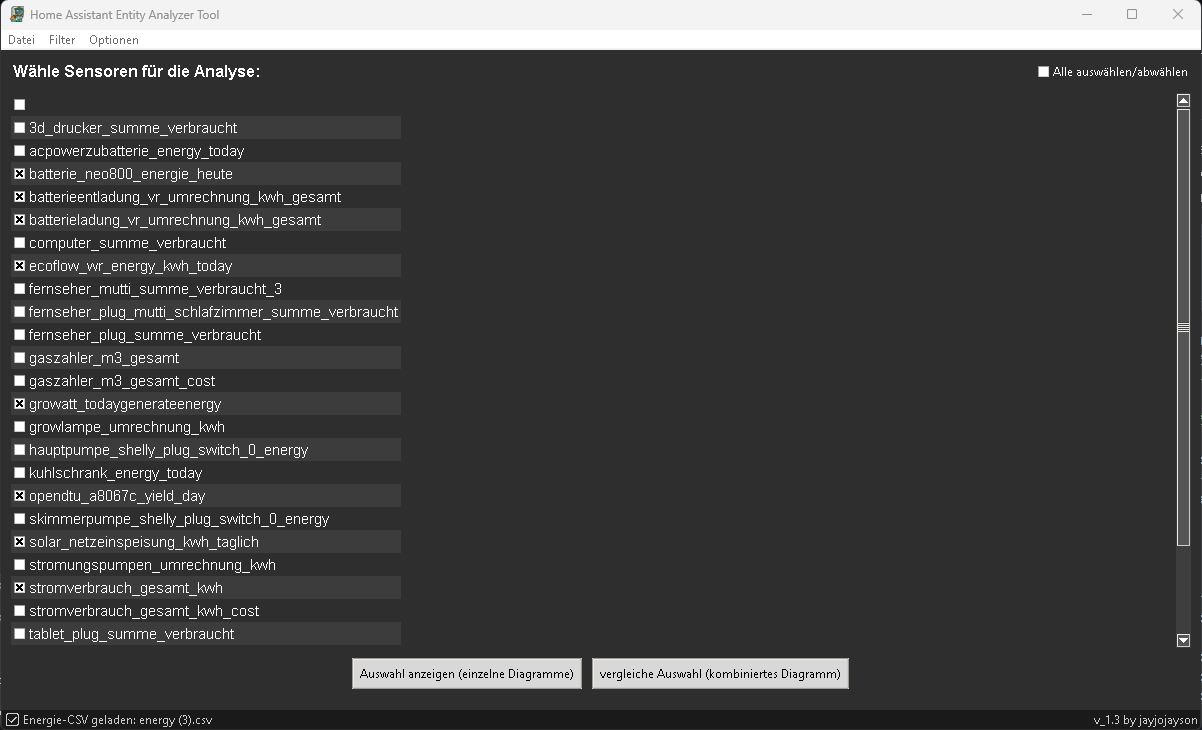
- Ihr könnt jetzt auch eure exportierte energy.csv mit dem Tool anschauen und analysieren.
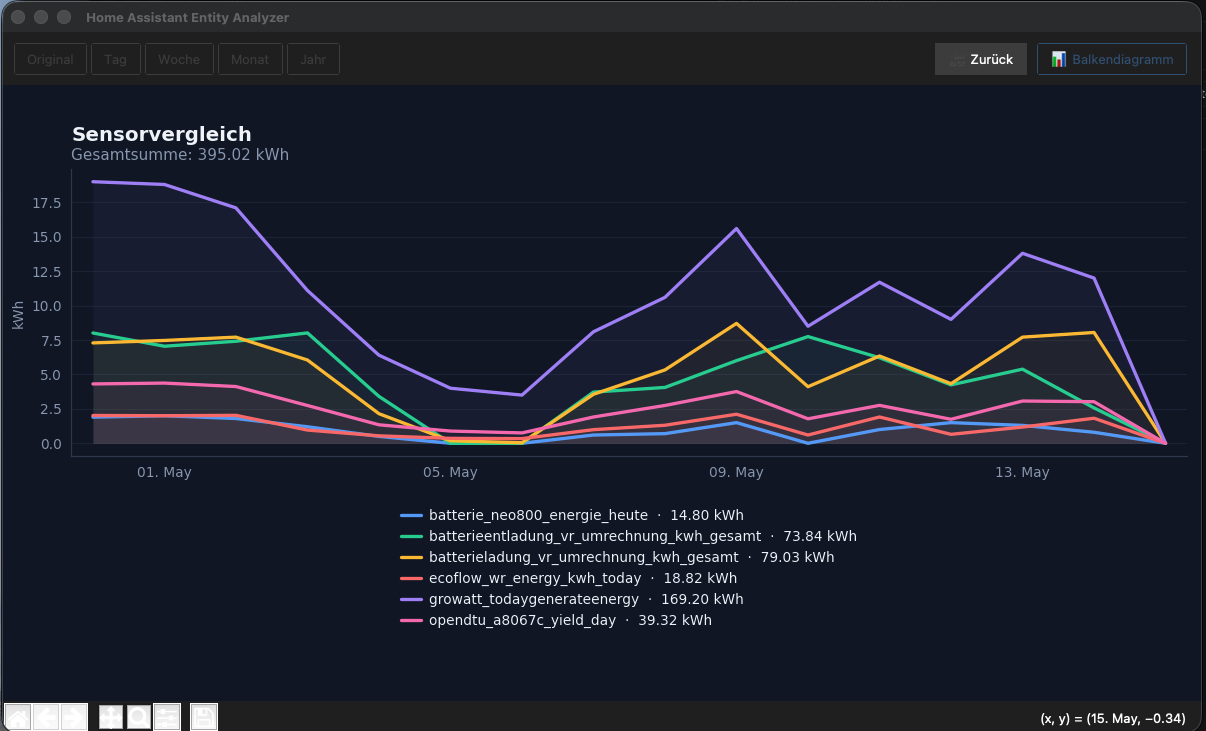
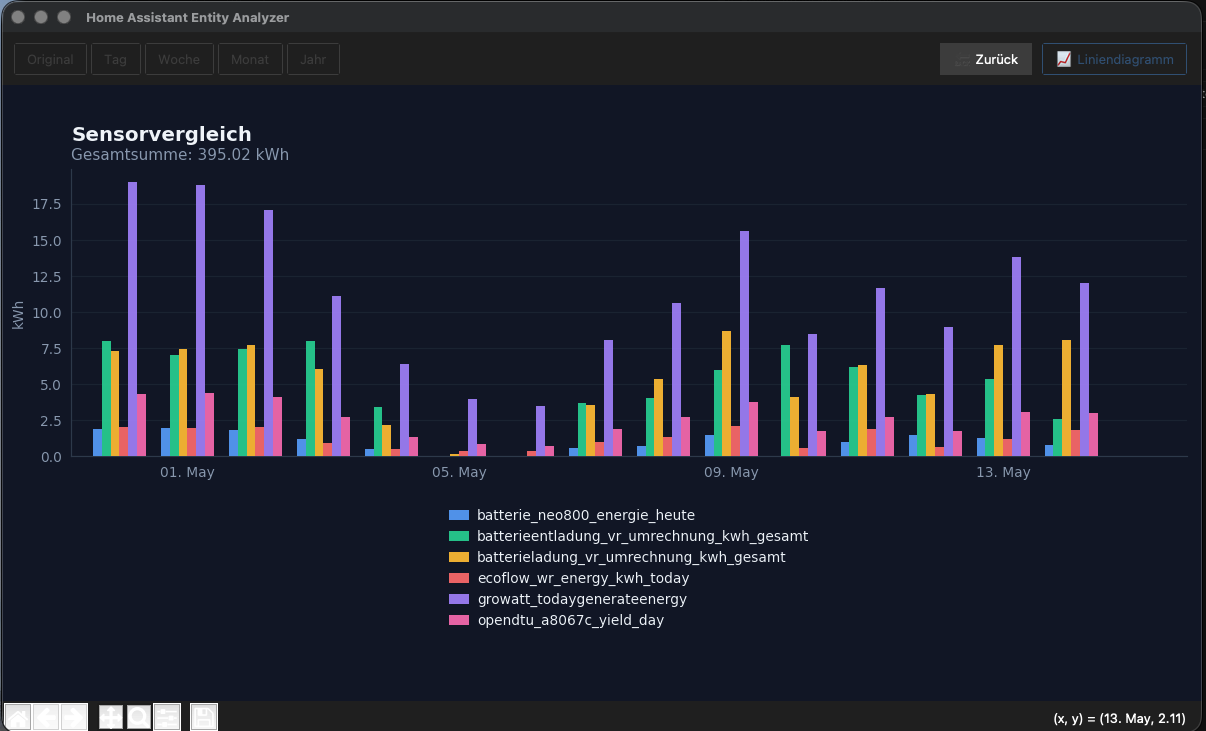
Ihr könnt die geänderte csv-Datei mit Semikolon Trenner auch direkt in Excel öffnen und einsehen. Wer sich dort ein wenig auskennt, kann schnell die obere Zeile fixieren und ein Filter auf die Tabelle anwenden. Damit hat man einen ähnlichen Funktionsumfang wie mit meinem Tool. Aber nicht so ein eine schöne Zusammenfassung wie in den letzten Bildern. ![]()
So hoffe nichts vergessen zu haben, ansonsten schreibt gerne und ich kann das hier noch entsprechend ergänzen. ![]()
Danke an @Nicknol für die Änderung der Formatierung von Komma in Semikolon Trenner.











